首先看一下程序的保护机制,注意,PIE是开启的,这个checksec检测PIE有时候不准确。不过,我们看到[NX是关闭的,说明堆栈的数据可以被当做指令执行]{.mark}

然后,我们用IDA分析一下,发现是一个很简单程序,并且只有添加和删除功能,其他功能未实现
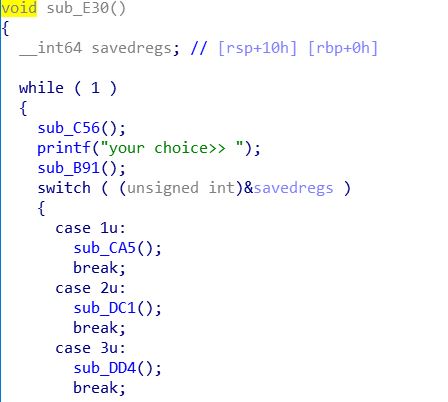
创建这里,有三处值得我们注意
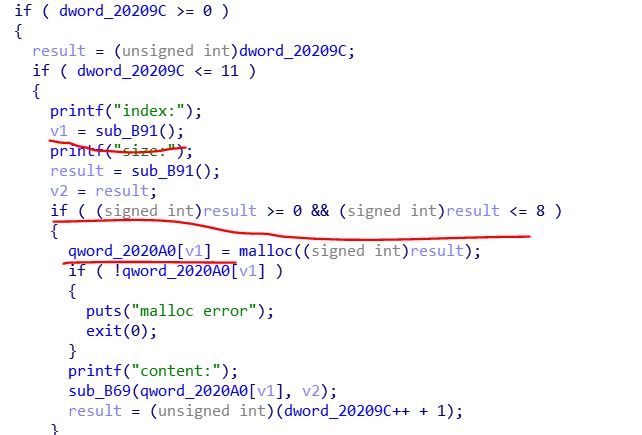
[创建的堆空间大小最多为8字节]{.mark}
[保存堆指针的数组下标可以越界]{.mark}
既然数组下标可以越界,那么我们就可以把任意的地方的8字节数据写成新建的堆的地址指针
[那么,通过数组越界,我们可以把一些函数的GOT表内容修改为堆指针,由于程序NX保护是关闭的,那么堆栈里的数据也可以当成指令执行。那么我们在堆里布置shellcode即可]{.mark}
有一点需要注意的是,我们的堆空间最多为8字节,并且我们最多向里面输入7字节数据
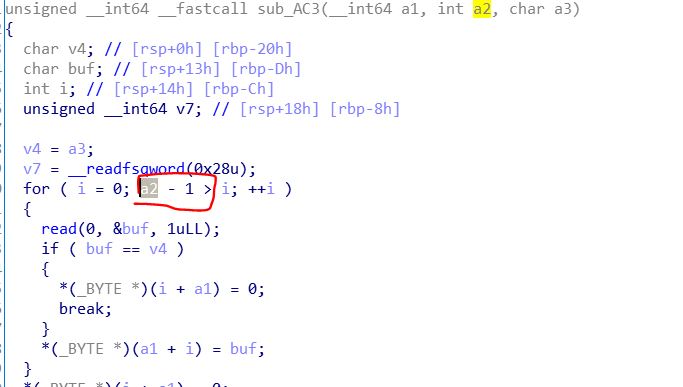
而我们的shellcode最少也要十几字节,因此,我们把shellcode分开,存储到多个堆里,然后在每个堆的最后2字节空间,填上jmp short xxxx指令,让它跳转到下一个堆里去执行代码。
Jmp short xxxx指令占用2字节,并且,这条指令使用的是[相对当前代码位置寻址,]{.mark} 为了发现规律,我们找几个现成的指令看看
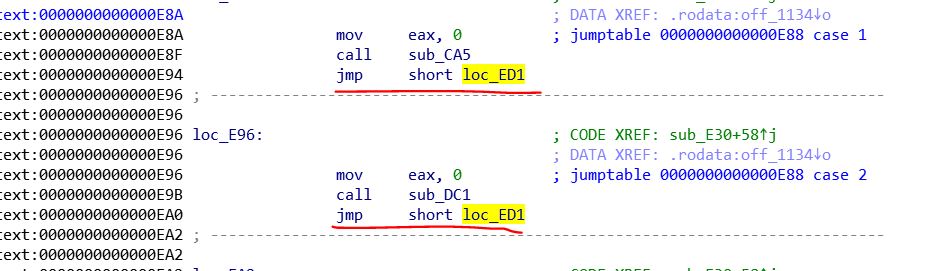
看看它们的十六进制

首先,我们计算第一个看看
0xE94 + 0x3B = 0xECF
0xEA0 + 0x2F = 0xECF
结果与目标地址还差2,因此,我们推断jmp short xxx中的xxx计算公式
[xxx = 目标地址-当前地址-2]{.mark}
经过试验和查阅资料,发现确实如此。
由于我们创建堆的时候是按顺序创建下来的,并且期间没有进行删除操作,我们的堆统一为8字节(根据64位堆的数据结构,至少保证有prev_size、size、fd、bk的空间,实际上的大小为8 align to 32 = 32字节),并且,使用中的堆块的fd和bk被当成数据区,因此我们的数据是从这里开始的,导致后面还有0x8字节空数据。

现在我们想从chunk0的jmp出跳到chunk1的data处执行新代码,那么我们jmp short后面的偏移为
注意那个末尾的1字节0,是输入函数给我们加上的,我们真正只能使用data区的7个字节,也就是我们的每个块里最多放7个字节的指令
Jmp short后面的next值的计算
[next = (8 + 8 + 8 + 1 + 2 - 2) = 0x19]{.mark}
现在我们就开始在堆里构造shellcode,我们的目的是在几个堆里构造处这样的代码
1 | ;64位系统调用 |
关键是rdi的值,在这里,如果我们将atoi的got表内容指向我们的第一个堆空间
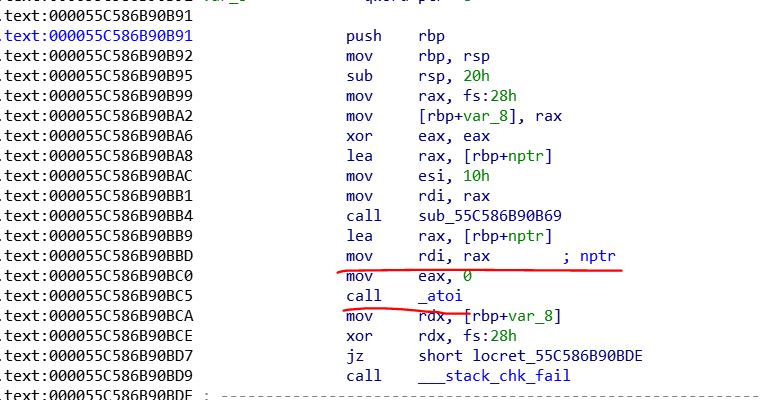
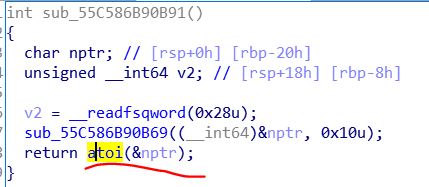
那么当我们下一次输入选项时,我们输入/bin/sh就直接get到了shell
因此,我们决定修改atoi的got表,让它指向我们的第一个堆
但是,修改atoi的GOT表操作必须放到最后一步,因为我们修改atoi的got表后,就不能再做其他功能了,因为输入选项不再有效,想想为什么?
但是,我们又得保证最后创建的那个堆位于其他几个堆的开头,即位于第一个堆,那么就可以先事先创建第一个堆用来占用那个空间,最后的时候delete掉后再申请回来(fastbin特性),通过数组越界把它的指针存到atoi的GOT表里。
[那么atoi的GOT表和数组下标的关系是什么呢?]{.mark}
我们的数组的静态地址在这

然后,atoi的GOT表静态地址在这
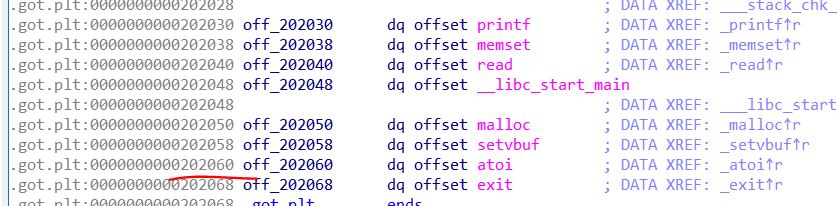
两者相差0x40字节,0x40 / 8 = 8字节,也就是说,数组下标-8处就是atoi的GOT表
综上,我们的exp脚本如下
1 | #coding:utf8 |
脚本中,某些指令有一些技巧,我们必须腾出2字节用于jmp,而某些指令一条就会占用7字节,因此我们换成其他指令,比如mov rsi,0这条指令,我们换成xor rsi,rsi,就有空间来写jmp指令了。