文章首发于安全KER https://www.anquanke.com/post/id/226065
0x00 前言
从两道题学习v8中JIT优化的CheckBounds消除在漏洞中的利用
0x01 前置知识
生成IR图
在运行d8时加一个--trace-turbo选项,运行完成后,会在当前目录下生成一些json文件,这些便是JIT优化时的IR图数据。
1 | ./d8 --trace-turbo test.js |
Turbolizer搭建
我们需要看懂v8的sea of node的IR图,v8为我们准备了一个可视化的IR图查看器Turbolizer,搭建Turbolizer的方法如下(先确保node.js为新版本)
1 | cd tools/turbolizer |
然后浏览器访问8000端口,即可使用该工具,按CTRL+L可以将v8生成的IR图数据文件加载进来可视化查看
sea of node学习
一个简单的示例,使用--trace-turbo运行
1 | function opt(f) { |
将生成的json文件用Turbolizer打开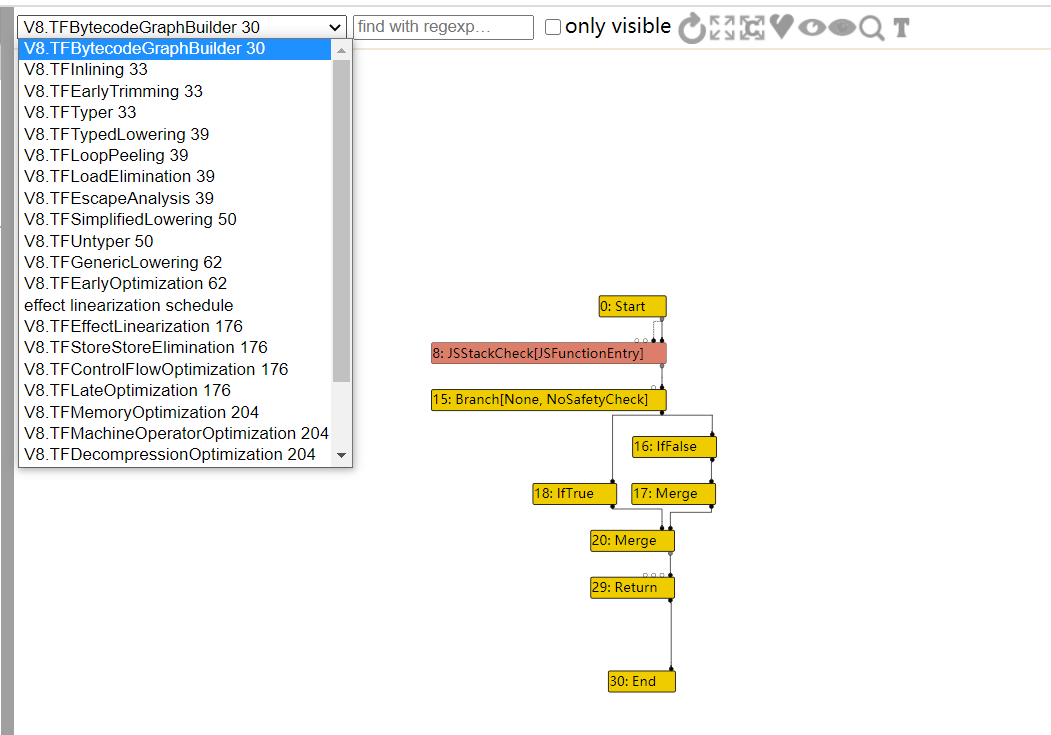
左上角有许多的阶段选择,后面的序号代表它们的顺序,首先是TFBytecodeGraphBuilder阶段,该阶段就是简单的将js代码翻译为字节码,点击展开按钮,我们将所有节点展开查看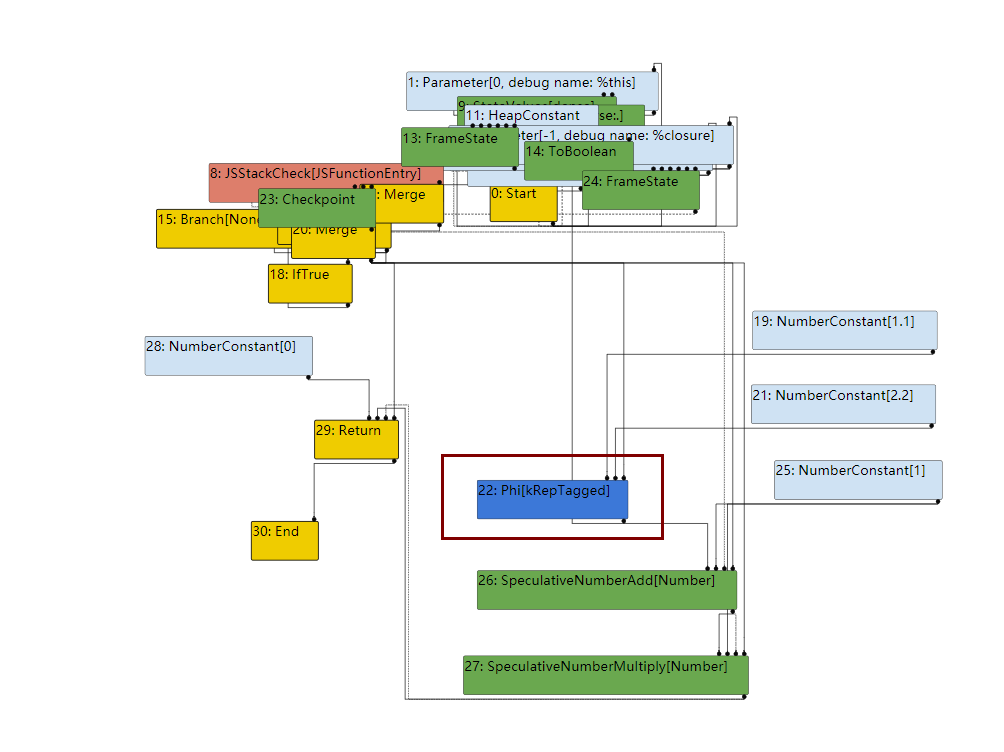
我们的var x = f ? 1.1 : 2.2;被翻译为了一个Phi节点,即其具体值不能在编译时确定,然后使用了SpeculativeNumberAdd和SpeculativeNumberMultiply做了x+=1;x*=1的运算。
接下来进入一个比较重要的阶段是TFTyper阶段,该阶段会尽可能的推测出节点的类型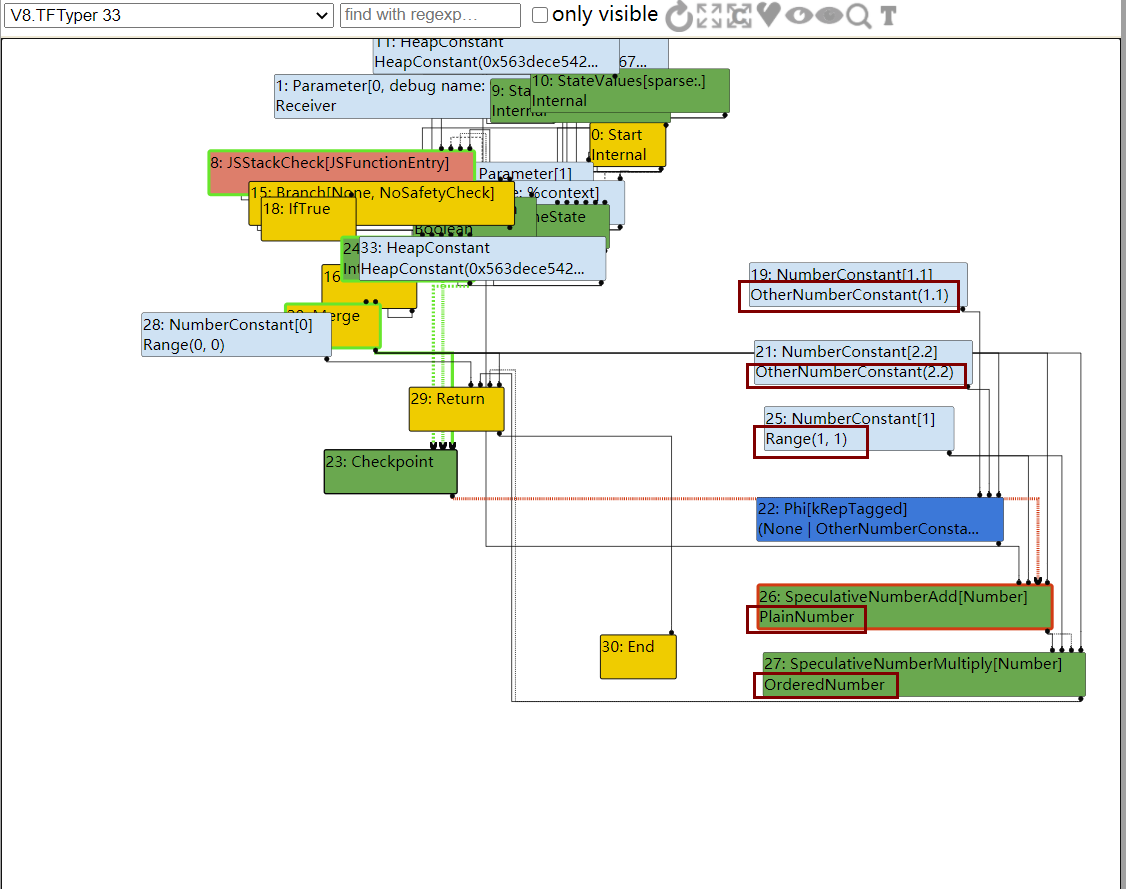
其中整数会使用Range来表示,接下来TFTypedLowering阶段会使用更加合适的函数来进行运算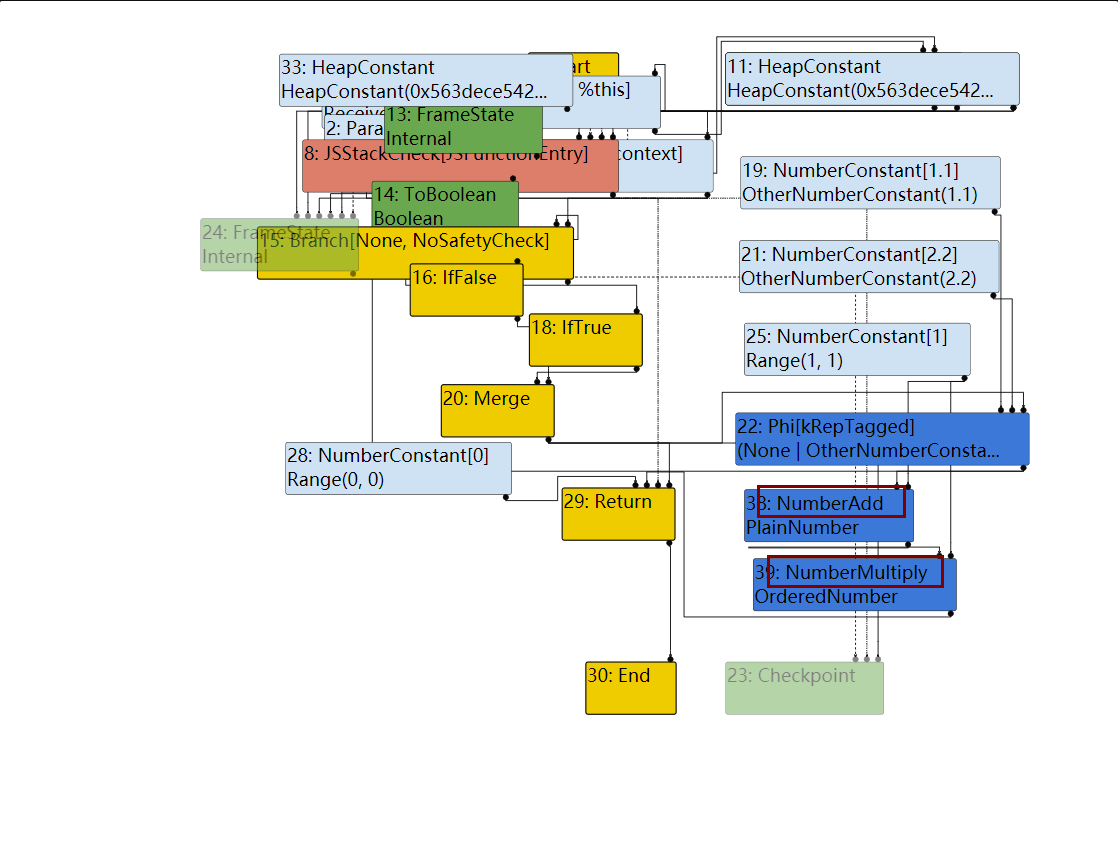
在TFSimplifiedLowering阶段,会去掉一些不必要的运算,然后统一类型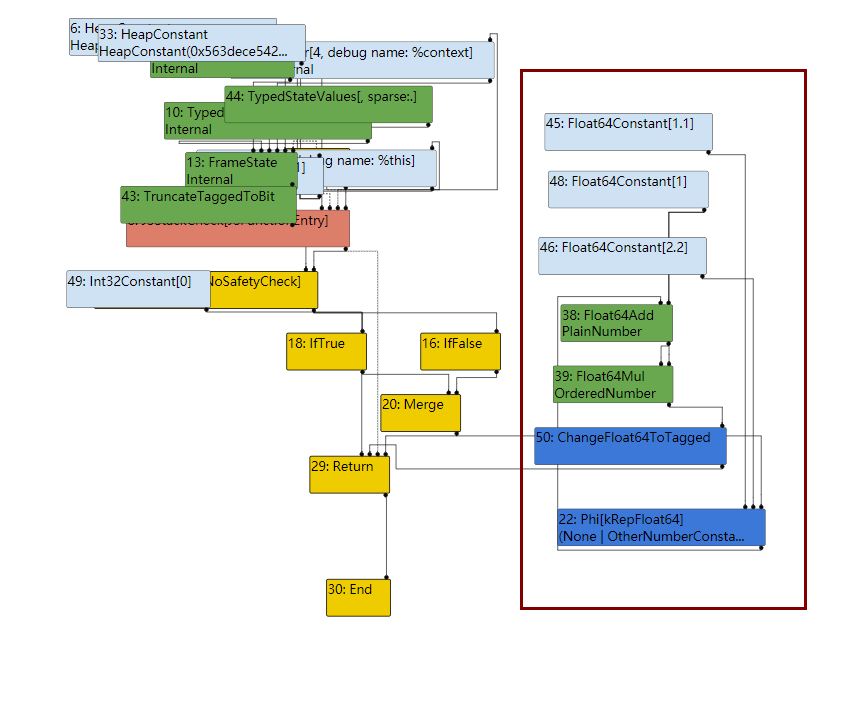
CheckBounds节点
在数组下标访问中, CheckBounds用来检查边界,如下一个简单示例
1 | function opt() { |
如图,在TFLoadElimination阶段,有CheckBounds检查下标是否越界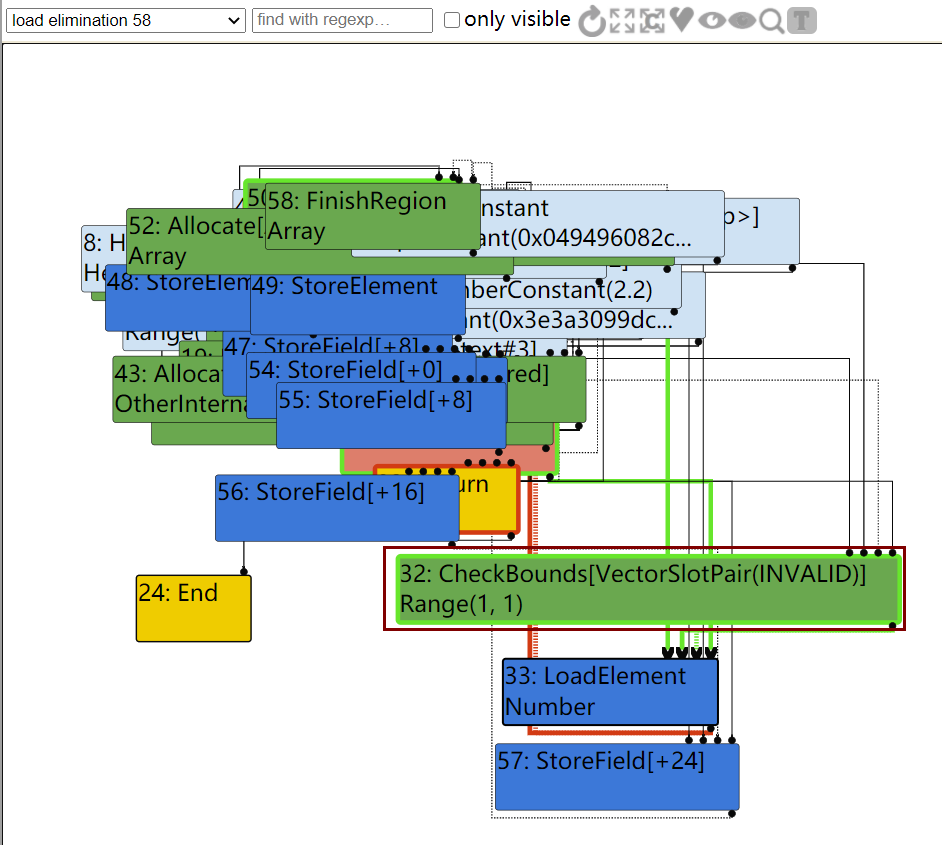
然而到了simplified lowering阶段,由于已经知道下标没有越界,因此可以直接去掉CheckBounds节点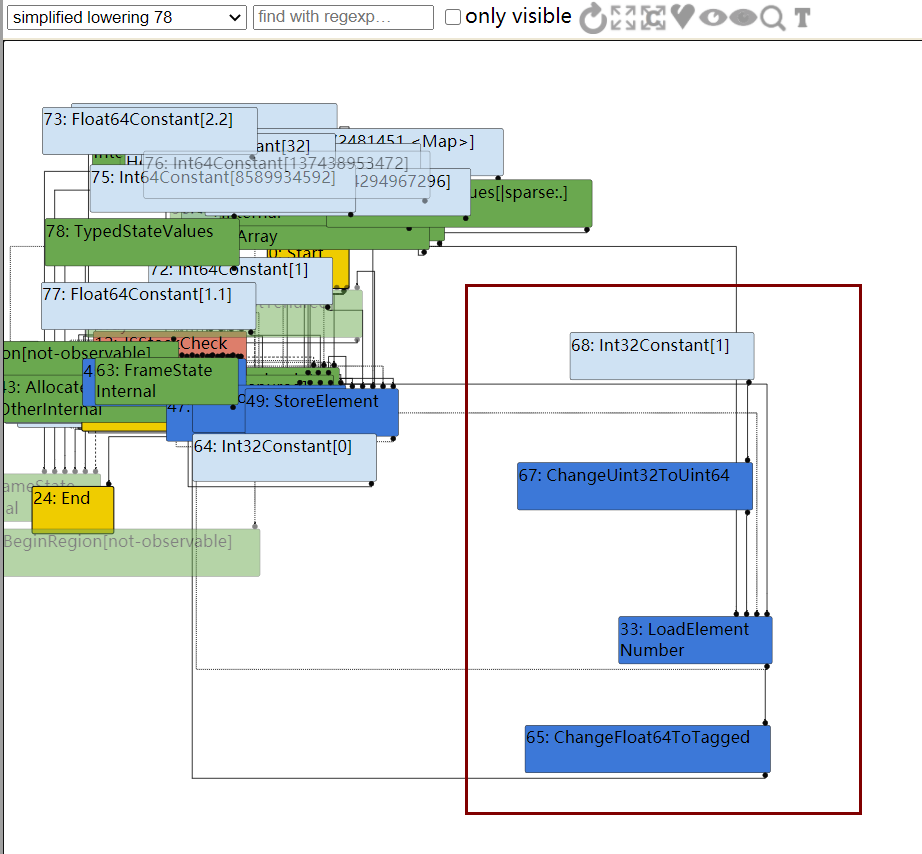
现在假如我们将arr对象放到opt函数外部,那么由于编译的是opt函数,arr的信息JIT不能完全掌握,便不会消除CheckBounds节点
1 | var arr = [1.1,2.2]; |
然而在最新版的v8中,不再有CheckBounds的消除,因为这个对于漏洞利用来说太方便了。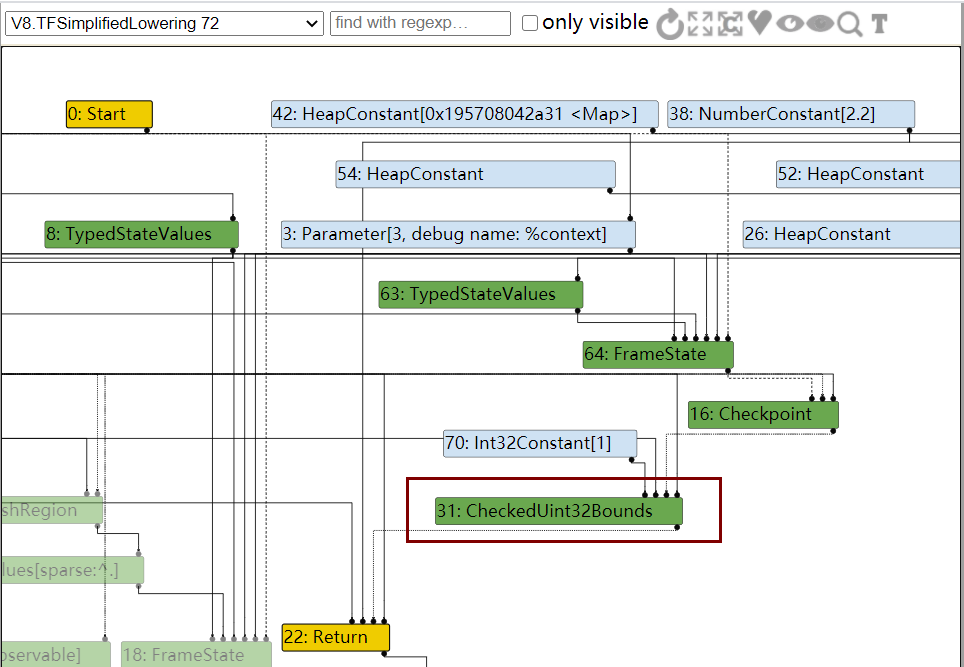
CheckBounds消除的利用
在数值的运算错误漏洞中,在javascript层和JIT优化的代码,两者计算的数值如果不一致,那么就可以利用这种CheckBounds消除来实现数组越界
0x02 google-ctf2018-final-just-in-time
patch分析
1 | diff --git a/BUILD.gn b/BUILD.gn |
patch文件在TypedLoweringPhase阶段增加了一个自定义的优化方案,它会检查该阶段的Opcode,如果遇到kNumberAdd,并且两个操作数为NumberConstant类型,那么就会将结果运算以后,替换节点
1 | +Reduction DuplicateAdditionReducer::Reduce(Node* node) { |
使用如下测试
1 | function opt(f) { |
在typer阶段时,使用了两次SpeculativeNumberAdd[Number]来进行加1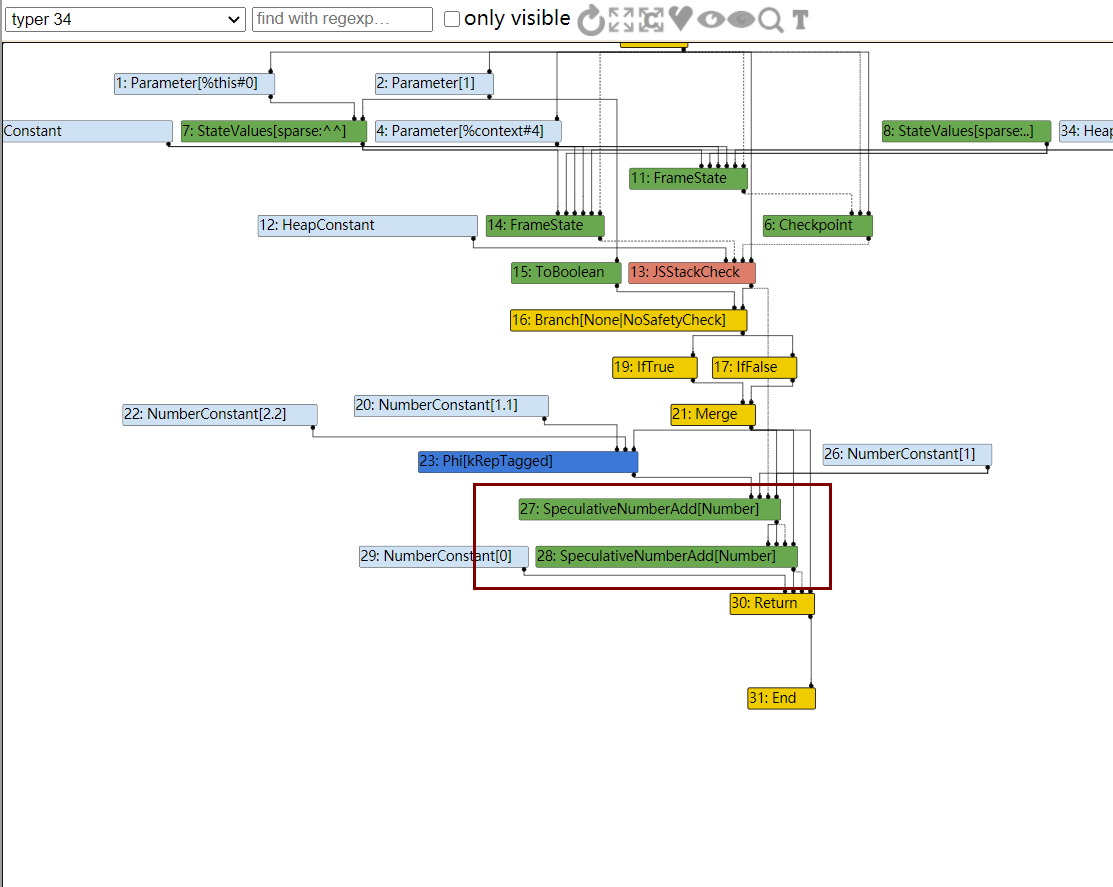
而到了TypedLowering阶段,由于使用的是NumberAdd,因此1+1直接被优化计算出来了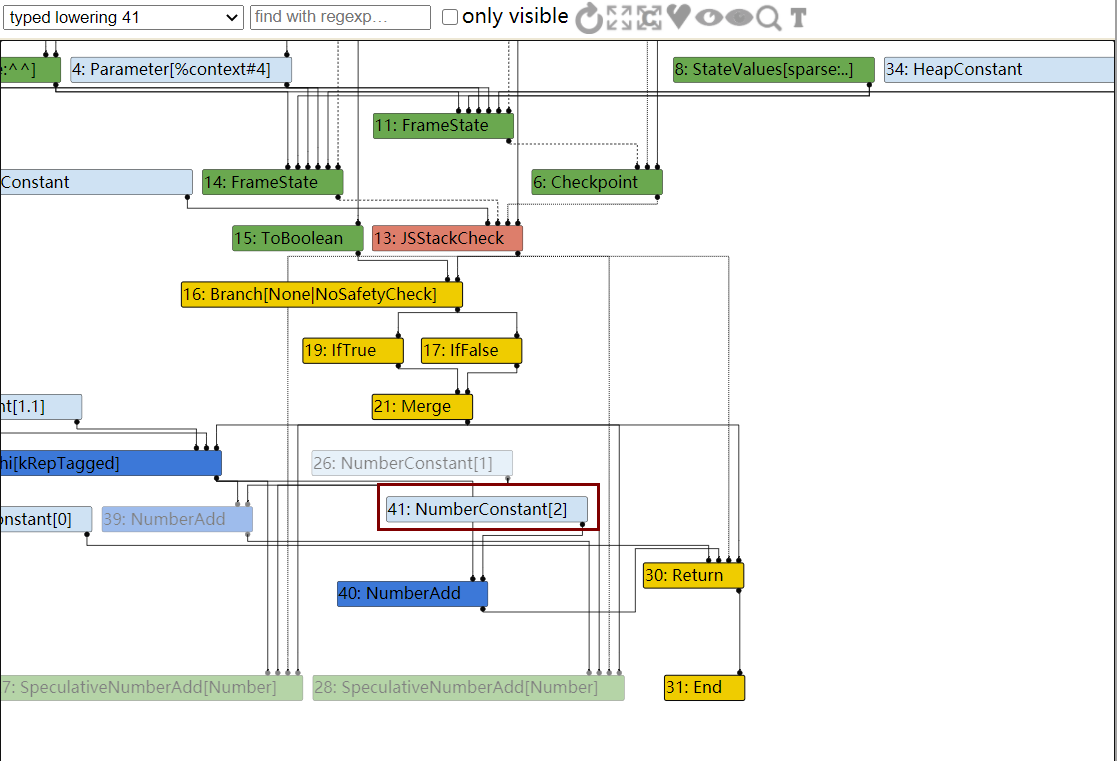
假如使用如下的代码,发现不会使用NumberAdd,由此知道NumberAdd出现在不同的数值类型之间
1 | function opt(f) { |
漏洞利用
需要借助IEE754的精度丢失来达到利用,在IEE754中,能够准确表示的最大整数为9007199254740991,大于这个数进行运算的话,会出现错误。
比如
1 | var x = 9007199254740991; |
而
1 | var x = 9007199254740991; |
因此,由于patch的加入,原本我们的x + 1 + 1与优化后的x + 2可能并不相等,那么就有可能在优化后造成数组越界。
首先构造
1 | function opt() { |
发现并没有成功越界,查看IR图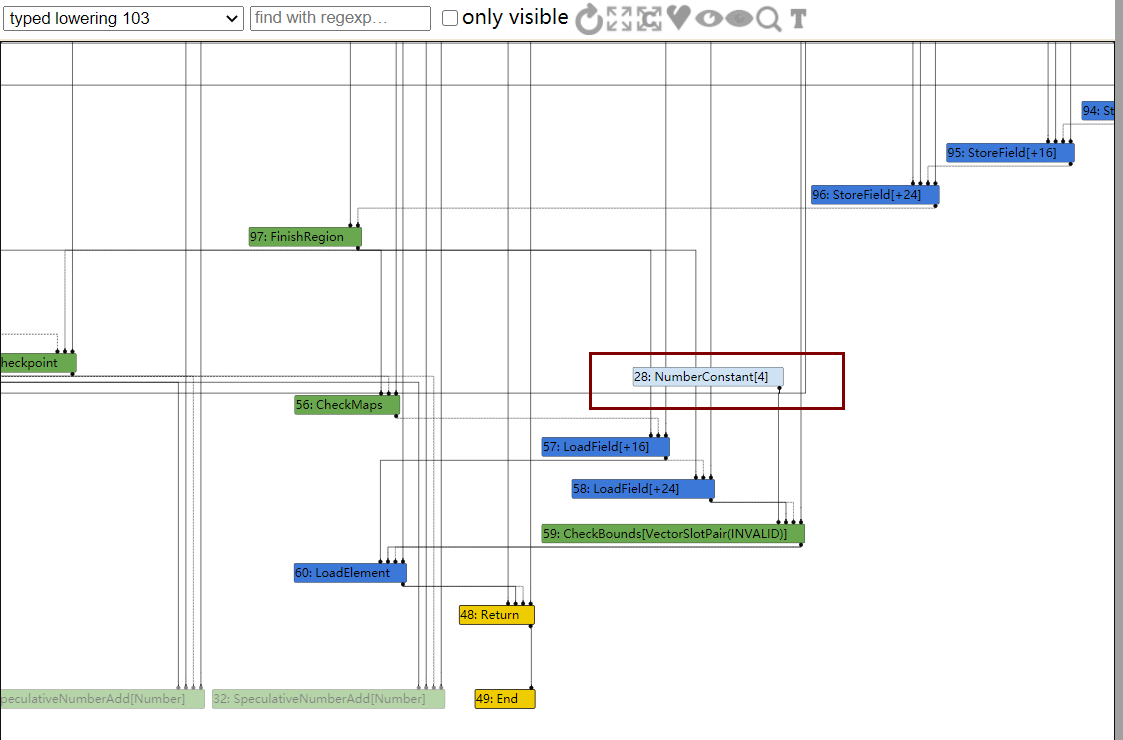
由于opt里面全都是NumberConstants,导致所有的加法都被优化了,而我们仅仅想要优化1+1,由此,我们可以构造一个Phi节点
1 | function opt(f) { |
发现这回成功溢出
1 | root@ubuntu:~/Desktop/google-ctf2018-final-just-in-time/debug# ./d8 1.js --trace-turbo |
分析IR图,patch的优化后于NumberAdd等,因此在最后一步减法NumberSubtract后,确定了Range(0,4),显然这个范围不会越界,但是接下来patch的优化将NumberAdd(1,1)优化为了2,那么最终结果已发生变化,但是没有更新CheckBounds的范围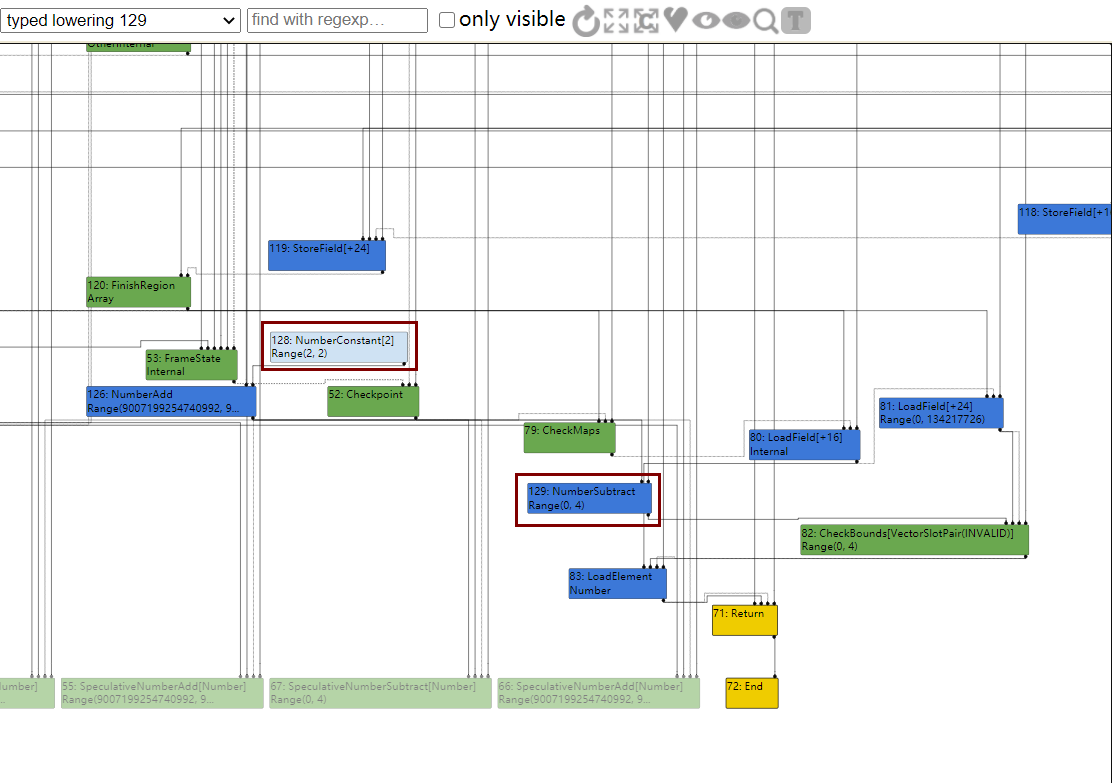
那么到达simplified lowering时,CheckBounds就会被移除,那么就可以溢出了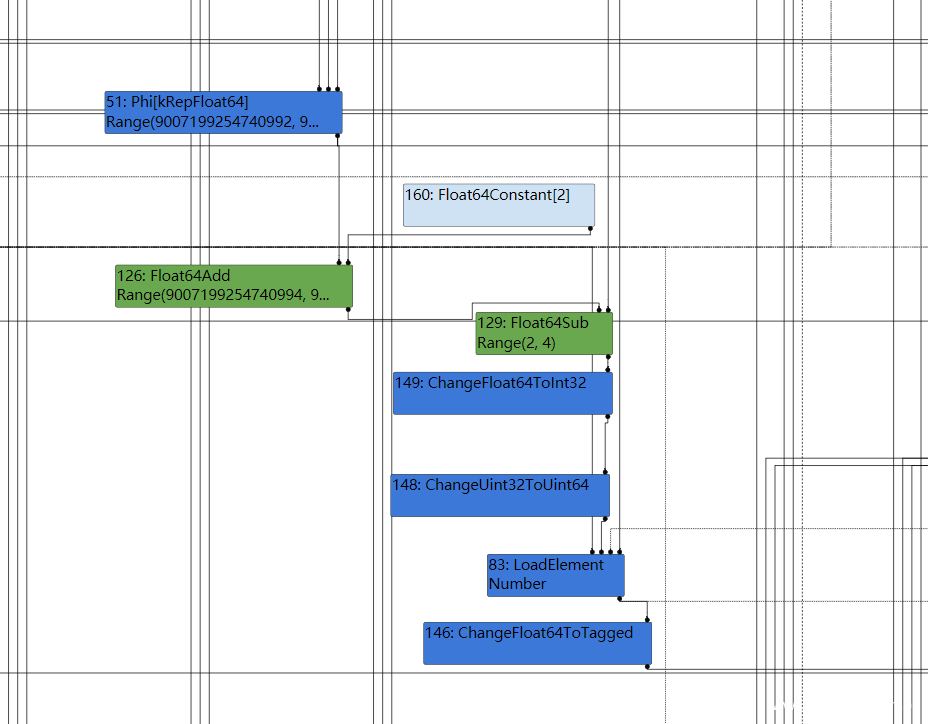
那么构造fakeObj和addressOf原语,然后利用即可
exp
1 | var buf = new ArrayBuffer(0x8); |
在addressOf_opt和fakeObj_opt中,我们没有直接返回arr[0]这是因为arr在opt函数内部,编译时收集的信息足够充分,即使我们改了map,也不影响其取出的值,因此,我们要返回整个arr对象。
0x03 35c3ctf-krautflare
patch分析
1 | commit 950e28228cefd1266cf710f021a67086e67ac6a6 |
这是一个v8的历史漏洞,patch将漏洞重新引入,其代号为880207,首先该漏洞出现在typer.cc中,因此猜测该漏洞出现在Typer阶段,并且该漏洞与Math.expm1(x)函数有关,Typer推断Math.expm1(x)函数的返回类型时,认为Math.expm1(x)的返回类型为PlainNumber或者Nan,却忽略了一种情况,那就是Math.expm1(-0),其返回值为-0,而-0属于HEAP_NUMBER_TYPE类型,在JIT编译时期与运行时期,就会有不一样的结果,比如
1 | Object.is(Math.expm1(-0),-0) |
在编译时期,JIT认为该值肯定为false,因为两者的类型不可能相等,但是在实际运行当中,Object.is(Math.expm1(x),-0),如果x为-0,那么结果就会为true。
漏洞利用
在javascript中,布尔类型可以直接做加减乘除运算
1 | false+1 |
因此,我们可以利用这种特性,将漏洞转换为一个数组越界,首先构造
1 | function opt(x) { |
用opt("0");是为了适配非PlainNumber类型的参数,这样最后一步调用opt(-0)不会进行deoptimization,运行发现,没有成功越界,查看IR图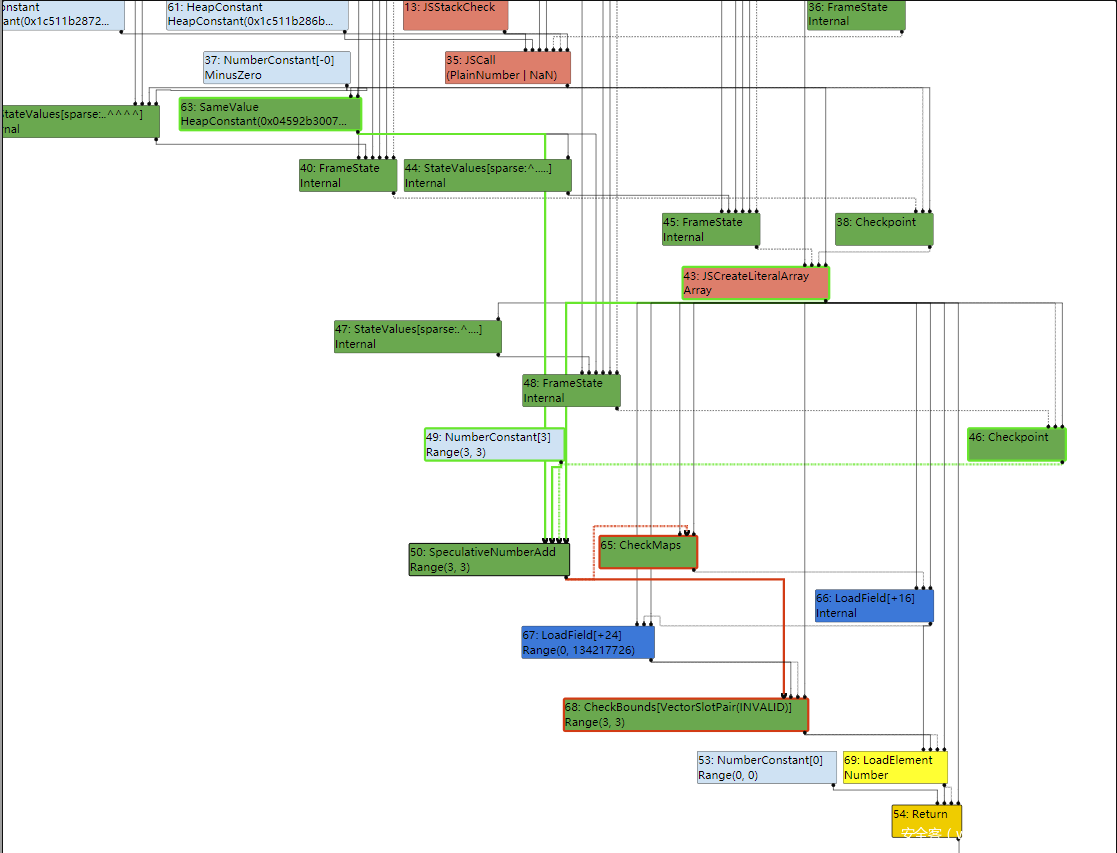
可以看到JSCall[PlainNumber | NaN],然后使用SameValue运算后,与3相加,最后得出范围Range(0,3)传给CheckBounds
然而到了TypedLowering阶段,发现下标直接变成了3,即发生常数折叠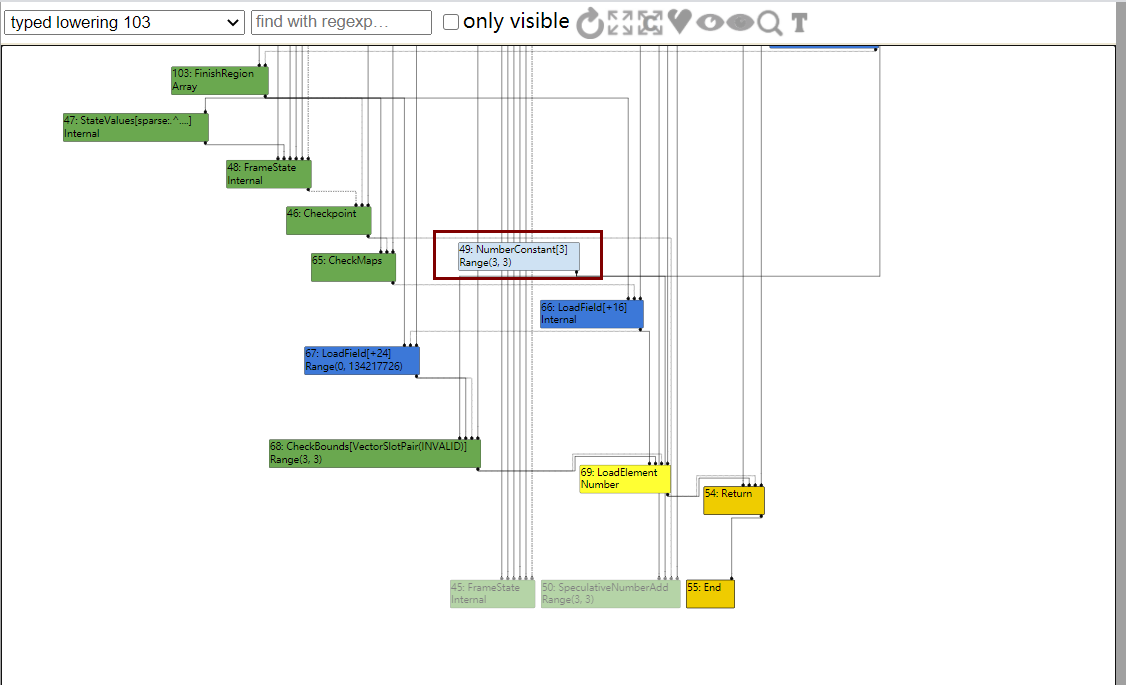
为了避免发生这样的常数折叠现象,我们可以使用一个字典对象来将我们的-0包含在内部,这样,只有在Escape Analyse阶段才能知道其值。
1 | function opt(x) { |
运行后发现确实发生了数组越界
1 | root@ubuntu:~/Desktop/krautflare# ./d8 1.js --trace-turbo |
查看IR图,这回在Typer阶段,还不能确定准确值,因此有一个范围Range(3,4)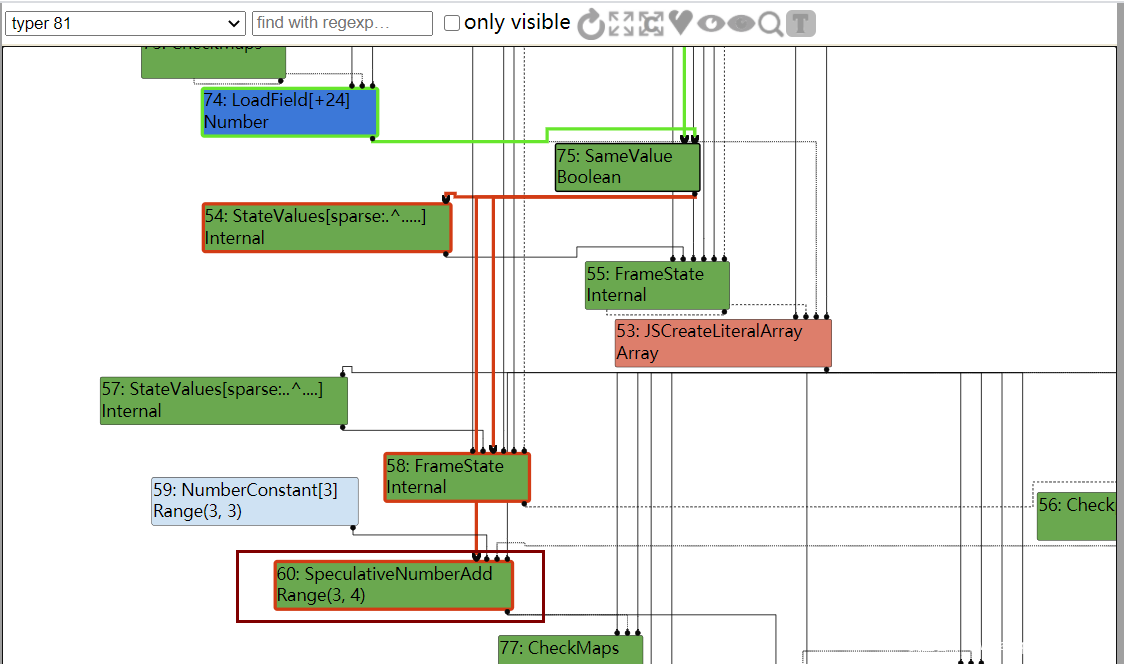
然后过了Escape Analyse阶段,才发现范围在Range(0,3)内,于是到了simplified lowering阶段,便把CheckBounds给去除了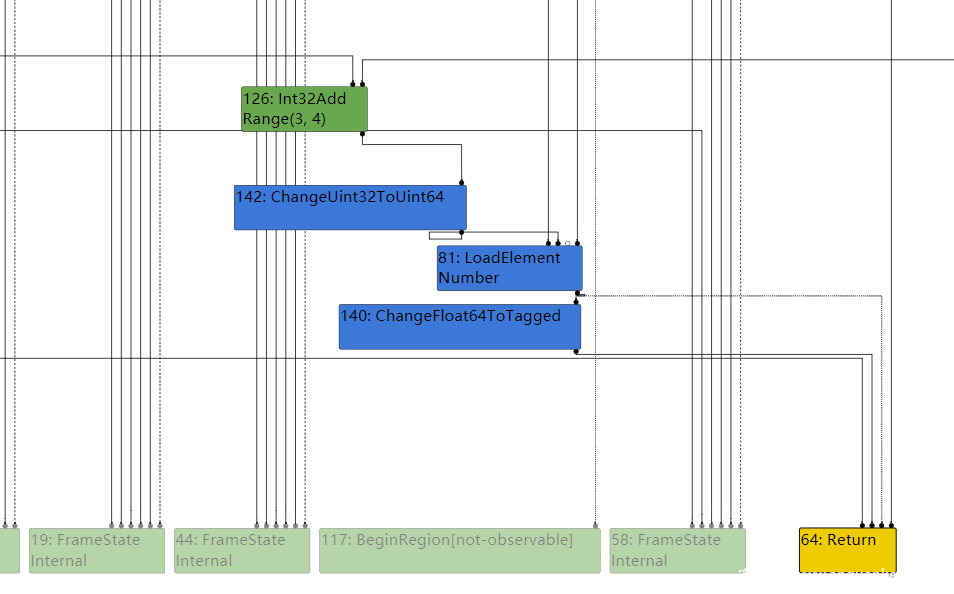
由此造成了溢出,可以利用溢出,构造一个oob_arr,来达到自由溢出,然后利用手法就一样了。
exp
1 | var buf = new ArrayBuffer(0x8); |
0x04 感想
在数值误差的漏洞当中,我们往往利用CheckBounds的消除来构造OOB数组,其中要保证这个数组是一个非逃逸对象,即在函数内部声明和使用,这样JIT收集的信息充分,才能决定是否要移除CheckBounds节点,似乎在新版本v8中,simplified lowering阶段不再去除该节点,以后遇到再看。
0x05 参考
从漏洞利用角度介绍Chrome的V8安全研究
introduction-to-turbofan
利用边界检查消除破解Chrome JIT编译器
关于2018_35c3ctf_krautflare的分析复现